#-*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import os
import json
import time
#导入避免被发现是selenium的工具
def browser_initial():
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(executable_path='../chromedriver.exe',options=option)
goal_url = 'https://www.zhihu.com/'
#未携带Cookies
browser.get('https://www.zhihu.com/')
return goal_url, browser
def log_ZHIHU(browser,goal_url):
# 从本地读取cookies
with open('ZhiHu_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': '.zhihu.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
'path': '/',
'httpOnly': False,
'secure': False
}
browser.add_cookie(cookie_dict)
browser.maximize_window()
#测试用搜索
time.sleep(10)
browser.get(url='https://www.zhihu.com/search?q=python%E4%BB%A3%E7%90%86ip&utm_content=search_suggestion&type=content')
return browser
def Seracr(browser):
Seracr_Input=browser.find_element_by_class_name('Input')
Text=input("输入你想搜索的文章的内容")
Seracr_Input.send_keys(Text)
Seracr_Button=browser.find_element_by_class_name('Button')
Seracr_Button.click()
if __name__ == '__main__':
tur = browser_initial()
bro=log_ZHIHU(tur[1],tur[0])
#Seracr(bro)
python 爬虫 登录知乎后搜索 某些文章 遇到的问题 代码补充

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新
 澈丹丶 2021-03-30 11:37关注
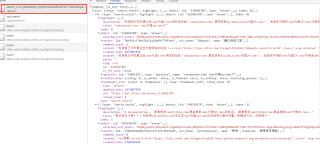
澈丹丶 2021-03-30 11:37关注你打开浏览器的控制台看下页面是不是有问题。而且这个页面的内容,并不是一次性请求过来的。你需要的内容,应该是https://www.zhihu.com/api/v4/search_v3?t=general&q=python%E4%BB%A3%E7%90%86ip&correction=1&offset=0&limit=20&lc_idx=0&show_all_topics=0 这个接口回来的数据,所以其实并不需要selenium,直接去模拟http get请求这个地址就可以了。
 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-03-29 11:59回答 4 已采纳 你打开浏览器的控制台看下页面是不是有问题。而且这个页面的内容,并不是一次性请求过来的。你需要的内容,应该是https://www.zhihu.com/api/v4/search_v3?t=genera
- 2021-03-29 09:24回答 2 已采纳 访问频率别太快,加个延时试试。。。如果偶尔成功,偶尔出问题的话,那试试retry
- 2022-02-12 16:41回答 2 已采纳 你对象错了,driver.get(url) 没有返回值,直接用driver就好了 # driver = webdriver.Edge(driver_path) # url = xxx
- 2024-01-01 23:42这个分享包涵了我开发的Python爬虫工具项目,主要用于合法爬取某些网页信息。以下是主要内容: 源代码:包括Python代码和相关脚本。这些代码展示了如何使用Python进行网页抓取、解析和数据提取。 项目文件:除了...
- 2021-03-29 19:49回答 5 已采纳 之前解决了问题忘了写答案了,现在补上一下 解决思路就是通过使用一个已经打开了的浏览器,来避免知乎发现是使用的selenium模块 添加如下代码即可 option = ChromeOp
- 2021-07-27 16:53回答 2 已采纳 返回零说明没有错误,通过我的检查发现你的选择返回的是空列表,说明你在匹配内容的时候没有匹配到,重新检查一下就行
- 2018-03-25 07:07回答 4 已采纳 头有问题啊!'Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/59.0'不知道怎么会出现...这种符号!自己去复制浏览器的user-ag
- 2020-12-25 06:00在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率。由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了一下...
- 2021-04-10 20:07回答 4 已采纳 对网站的多次请求时,要模仿浏览器浏览的一样,要有时间间隔不能过于频繁,尽量把请求头写全写对,针对题主的问题,1.csrf_token的获取要从页面分析着手,主要是在页面代码中meta 或其他地方找;二
- 2022-05-20 12:09回答 2 已采纳 如果登陆了,会缓存在浏览器端。每次请求接口时会携带这个sessionId,包含在cookies中。
- 2021-10-05 00:13回答 3 已采纳 返回的值不符合json规范,先返回文本,打印内容看看,再做处理。
- 2020-09-21 07:44在爬虫过程中,有些页面在登录之前是被禁止抓取的,这个时候就需要模拟登陆了,下面这篇文章主要给大家介绍了利用Python爬虫模拟知乎登录的方法教程,文中介绍的非常详细,需要的朋友可以参考借鉴,下面来一起看看吧...
- 2021-12-22 16:07回答 2 已采纳 代码没问题,cookie过期了,重新登录通过浏览器获取最新cookie就能获取到内容了
- 2019-07-31 17:07利用Python网络数据采集技术的爬虫代码demo,可以提供给爬虫初学者参考。
- 2021-03-06 17:03Hanlvvisa-黄先生的博客 知乎类似于一个论坛,讨论度比百度高一些,那你知道如何用python爬虫爬知乎网站吗?其实如果直接爬取很容报错,我们可以通过浏览器伪装爬取。1、python爬虫工作原理python爬虫通过URL管理器,判断是否有待爬URL,...
- 没有解决我的问题, 去提问



问题事件
 系统已结题
2月11日
系统已结题
2月11日 已采纳回答
2月3日
已采纳回答
2月3日
悬赏问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码
- ¥15 js调用html页面需要隐藏某个按钮
- ¥15 ads仿真结果在圆图上是怎么读数的
- ¥20 Cotex M3的调试和程序执行方式是什么样的?
- ¥20 java项目连接sqlserver时报ssl相关错误
- ¥15 一道python难题3