
大佬们,我想问一下,为什么python保存到本地的HTML页面用浏览器打开后很多东西都加载不出来呢,页面的布局也很不一样,下面是我写的保存B站HTML页面
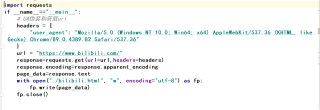
然后爬出来的HTML打开的页面是这个样子的
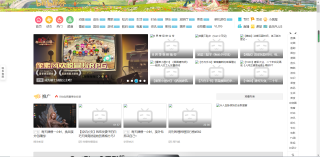
但是他原页面是这个样子的
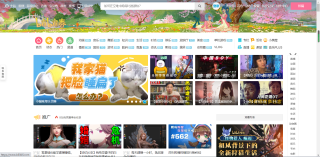
这是怎么回事啊,求大佬们指点!!!

大佬们,我想问一下,为什么python保存到本地的HTML页面用浏览器打开后很多东西都加载不出来呢,页面的布局也很不一样,下面是我写的保存B站HTML页面
然后爬出来的HTML打开的页面是这个样子的
但是他原页面是这个样子的
这是怎么回事啊,求大佬们指点!!!
 分享
分享 分享
分享

