import requests
import re
url='http://www.netbian.com/s/chuyinweilai/'
head={
'user_agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
page_data=requests.get(url,headers=head).text
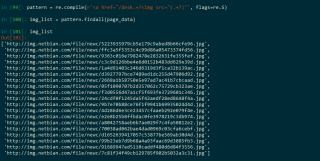
pattern=re.compile(r" #此处为可匹配图片的正则表达式 ")
str=r''
print(pattern.search(str))
问:“#此处为可匹配图片的正则表达式”应该填什么?
还请您动动您的手指,告诉鄙人答案