关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
骑着蜗牛ひ追导弹'
2021-03-31 08:37
采纳率: 55.6%
浏览 70
首页
大数据
已采纳
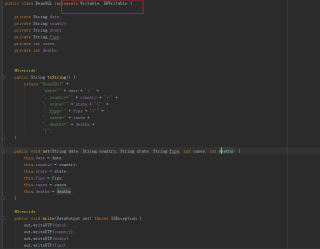
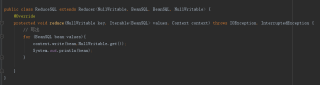
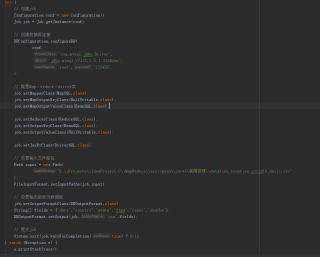
MapReduce将本地数据读入数据库报错 java.io.IOException
big data
其他
开发语言
java
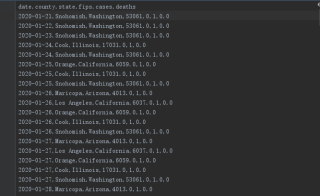
原始数据集
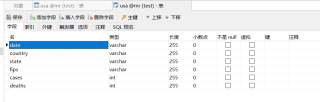
数据库建表存储结果
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
沐川
2021-03-31 08:47
关注
你要贴在代码框里,大家可以拷贝了运行,不然,纯人肉看,成本太高,大家就不愿意回答你的问题,你可能就要花很长的时间自己研究。
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
读取集群中HDFS上的文件
报错
Error:
java
.
io
.
IOException
: Filesystem closed at org.apache.hadoop.hdfs.DFSCl
2022-06-07 22:46
QYHuiiQ的博客
在
MapReduce
中读取HDFS上的文件时
报错
: 这是因为每个datanode使用的是同一个Configurat
io
n对象,节点在访问文件系统时会根据Configurat
io
n对象创建一个FileSystem实例(我的自定义Mapper中的代码):创建的这个...
Caused by:
java
.
io
.
IOException
: Path: //single is a directory
2022-03-16 12:00
布丁味的博客
Caused by:
java
.
io
.
IOException
: Path: //single is a directory, which is not supported by the record reader when `
mapreduce
.input.fileinputformat.input.dir.recursive` is false. 问题解决 spark
读入
的...
执行
MapReduce
程序的参数类型问题导致
报错
2024-01-04 13:43
英年不秃的博客
错误原因是参数类型不统一:这个异常表示在执行
MapReduce
作业时,键的类型不匹配。期望的键类型是org.apache.hadoop.
io
.Text,但实际接收到的类型是org.apache.hadoop.
io
.LongWritable。请检查代码中涉及到键类型的...
【
大数据
】
MapReduce
JAVA
API编程实践及适用场景介绍
2024-05-25 16:52
_BugMan的博客
一文详解,
MapReduce
JAVA
API以及适用场景介绍。
18、
MapReduce
的计数器与通过
MapReduce
读取/写入
数据库
示例
2023-05-01 12:04
一瓢一瓢的饮 alanchanchn的博客
在执行
MapReduce
程序的时候,控制台输出日志中通常有下面所示片段内容Hadoop内置的计数器可以收集、统计程序运行中核心信息,帮助用户理解程序的运行情况,辅助用户诊断故障下面是示例性日志,介绍了计数器。
将
MapReduce
的结果导入到
数据库
中
2019-03-29 13:02
wen-pan的博客
有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如要将我们一堆
数据
的分析结果存储到我们的关系型
数据库
中以便于在web程序中进行查询显示,这时候我们就需要
mapreduce
与 mysql 进行
数据
的交互。...
Java
中的
mapreduce
没了_
MapReduce
学习踩坑指南
2021-03-12 21:36
weixin_39989949的博客
MapReduce
学习踩坑指南关于
java
及jar包的import问题踩坑1错误: 程序包org.apache.hadoop.conf不存在或者其他的类似于程序包org.apache.hadoop.*不存在的问题如果你出现 找不到org.apache.commons.cli.Opt
io
ns的类...
大数据
实战——基于Hadoop的
Mapreduce
编程实践案例的设计与实现
2023-08-25 10:15
ZShiJ的博客
通过充分利用分布式计算,Hadoop实现了对大规模
数据
的高效处理,使得复杂的
数据
分析任务变得...通过这一实践案例,我们可以深入了解Hadoop的
MapReduce
编程模型,以及如何在实际应用中利用其优势来处理和分析海量
数据
。
数据
研发学习笔记4.6:
大数据
之
MapReduce
2020-05-17 10:17
Lynn Wen的博客
文章目录1 概述1.1 分布式并行编程1.2
MapReduce
模型简介1.3 Map和Reduce函数2
MapReduce
体系结构3
MapReduce
工作流程3.1 工作流程概述3.2
MapReduce
各个执行阶段3.3 Shuffle过程详解3.4
MapReduce
应用程序执行过程4...
Hadoop 中利用
mapreduce
读写 mysql
数据
2019-10-08 21:15
aibiba0894的博客
有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv、uv
数据
,然后为了实时查询的需求,或者一些 OLAP 的需求,我们需要
mapreduce
与 mysql 进行
数据
的交互,而这些是 hbase 或者 hive 目前...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告


 分享
分享


