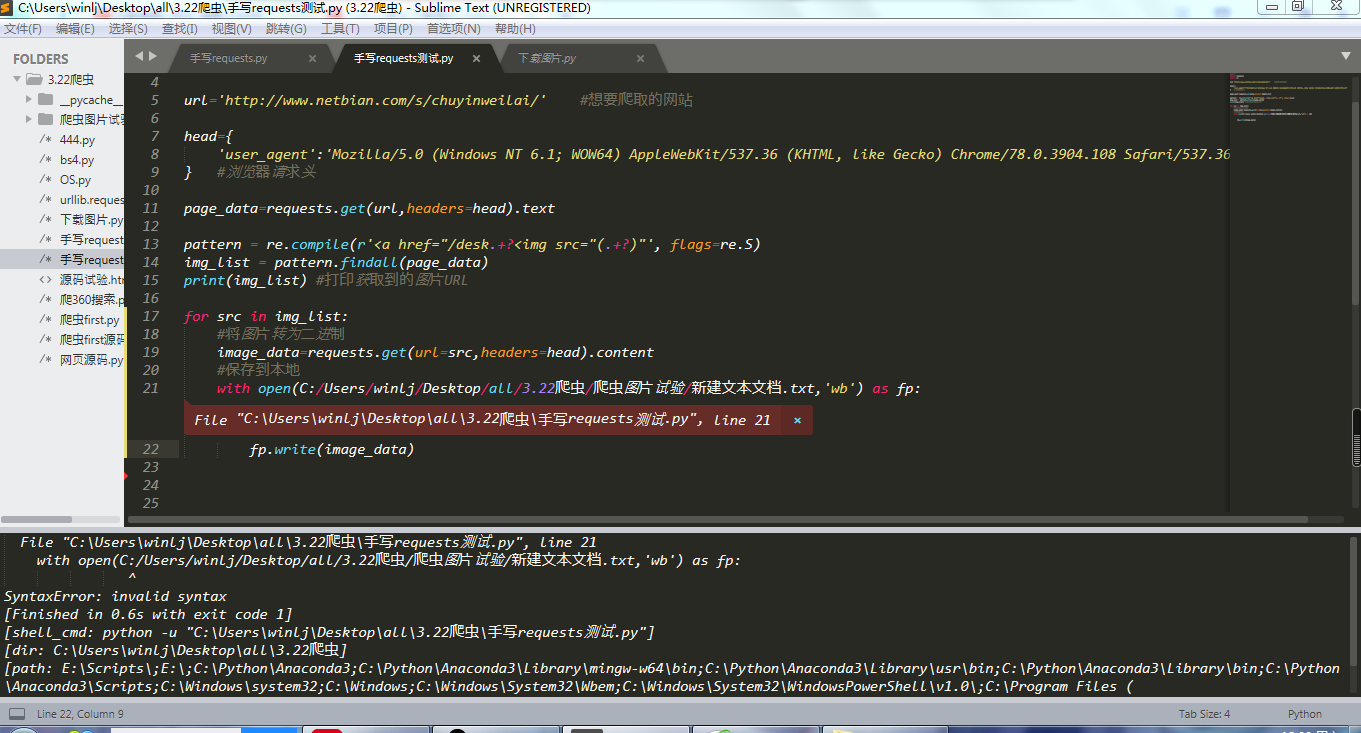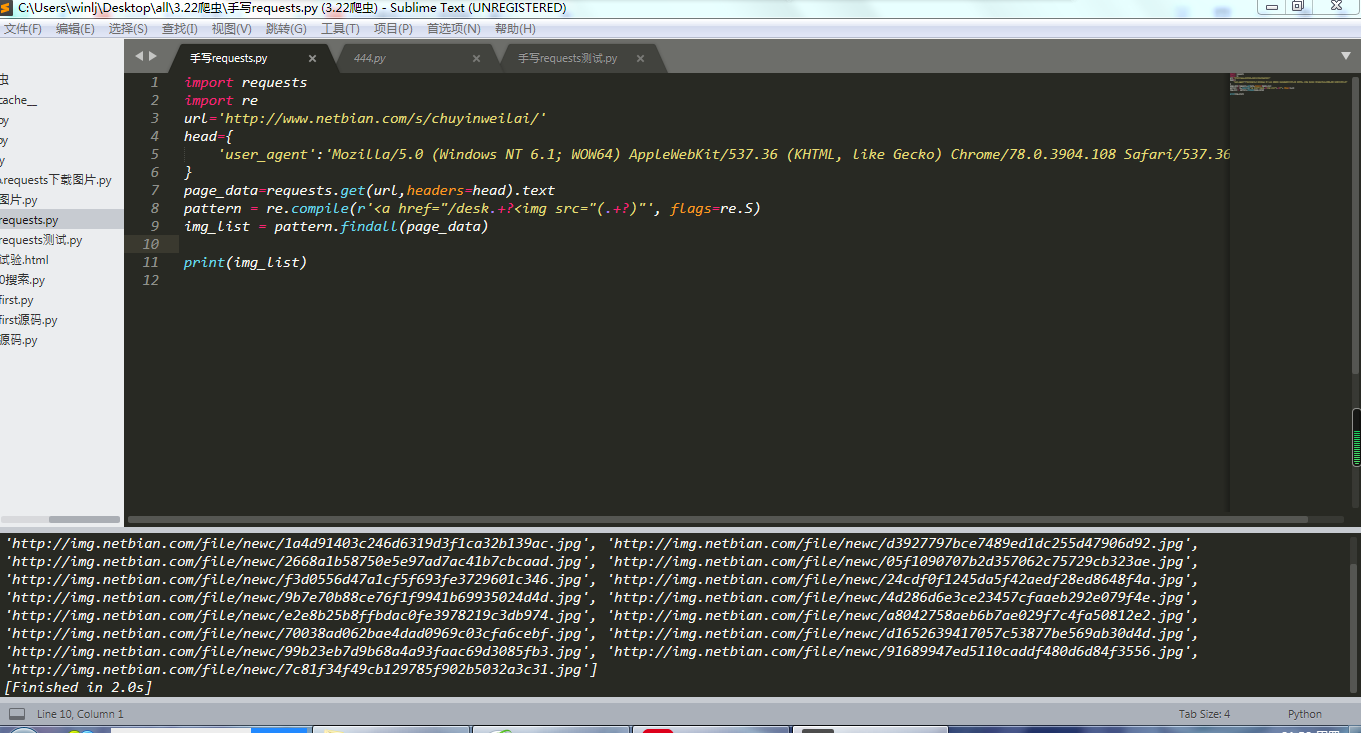
从图中可以看到,我已经获取到了图片的URL了,现在我想将这些图片下载回来,那我该使用什么代码?
import requests
import re
url='http://www.netbian.com/s/chuyinweilai/'
head={
'user_agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
page_data=requests.get(url,headers=head).text
pattern = re.compile(r'<a href="/desk.+?<img src="(.+?)"', flags=re.S)
img_list = pattern.findall(page_data)
print(img_list)