简单明了,问题就是如何批量保存而不是只保存一张?我这个代码应如何修改?
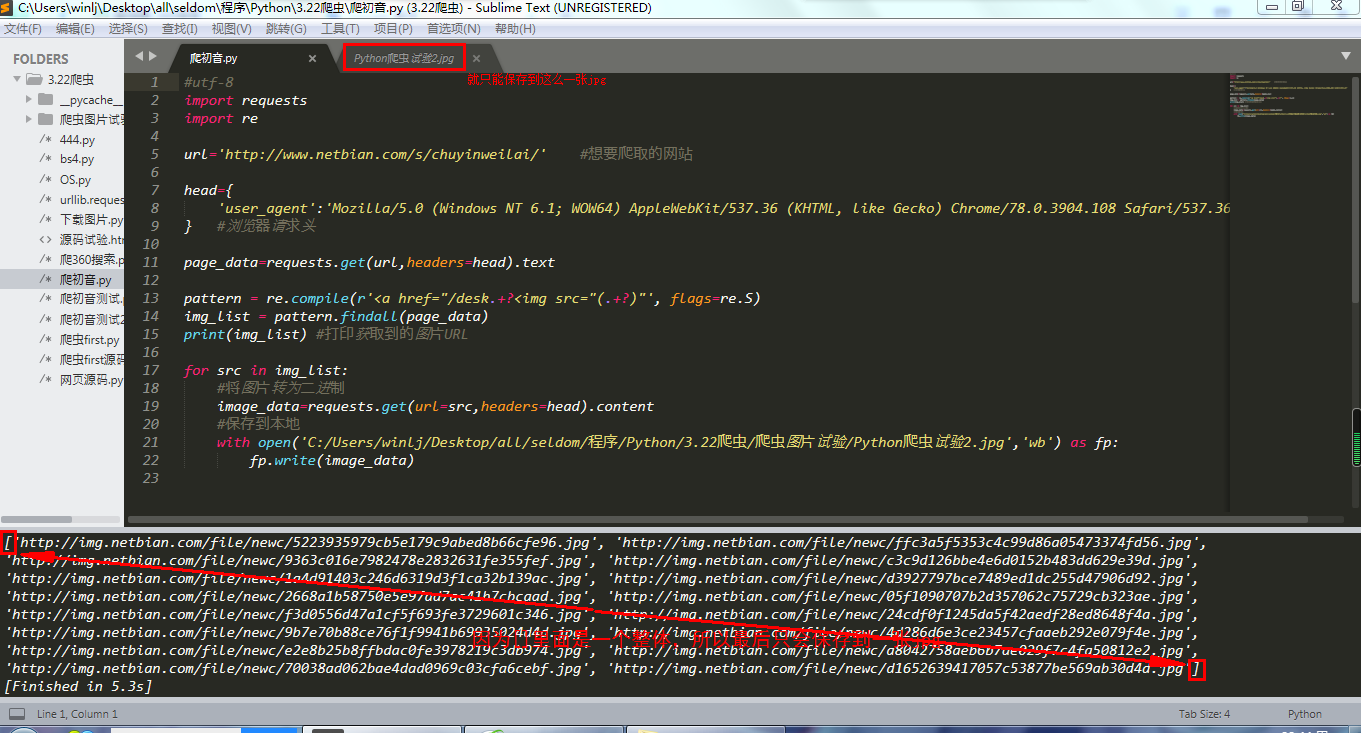
以下是我的代码:
#utf-8
import requests
import re
url='http://www.netbian.com/s/chuyinweilai/' #想要爬取的网站
head={
'user_agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
} #浏览器请求头
page_data=requests.get(url,headers=head).text
pattern = re.compile(r'<a href="/desk.+?<img src="(.+?)"', flags=re.S)
img_list = pattern.findall(page_data)
print(img_list) #打印获取到的图片URL
for src in img_list:
#将图片转为二进制
image_data=requests.get(url=src,headers=head).content
#保存到本地
with open('C:/Users/winlj/Desktop/all/seldom/程序/Python/3.22爬虫/爬虫图片试验/Python爬虫试验2.jpg','wb') as fp:
fp.write(image_data)