我在百度搜索"柠檬班",然后想定位"柠檬班吧-百度贴吧"这个a标签。F12,然后用//a[text()="吧 - 百度贴吧
"]文本内容是复制粘贴进去的,定位失败。想问问各位大帅比,大漂亮,这是怎么回事呢?是不是因为文本中用换行符和空格呢?
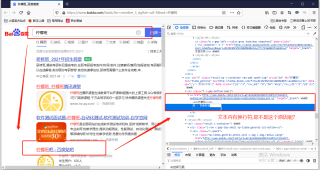

我在百度搜索"柠檬班",然后想定位"柠檬班吧-百度贴吧"这个a标签。F12,然后用//a[text()="吧 - 百度贴吧
"]文本内容是复制粘贴进去的,定位失败。想问问各位大帅比,大漂亮,这是怎么回事呢?是不是因为文本中用换行符和空格呢?
 分享
分享
对技术追求有强迫症是好事,可以不断取得进步。对于a节点的定位,经测试需要在请求头添加Accept-Language,用绝对路径a//text(),获取该节点下的所有文本内容。附代码:
headers = {'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6'}
response = requests.get('https://www.baidu.com/s?wd=柠檬班',
headers=headers)
root=etree.HTML(response.text)
result = ''.join([x.strip() for x in root.xpath('//*[@id="3"]/h3/a//text()') if x!=' '])
print(result)
#输出:
柠檬班吧 - 百度贴吧
分享


