
目的:想将相邻年份数据,IDind相同的数据(意思是该个体两个年份都有,其他的先不要)保留,生成的数据只有两个年份 个体相同的平衡数据。
年份包括:
例如 保留1989年和1991年IDind为111101012的数据。
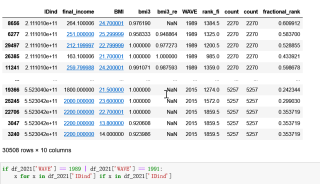
if df_2021['WAVE'] == 1989 | df_2021['WAVE'] == 1991:
将筛选后df_2021保留成df_1991
elif df_2021['WAVE'] == 1991 | df_2021['WAVE'] == 1993:
将筛选后df_2021保留成df_1993
elif df_2021['WAVE'] == 1993 | df_2021['WAVE'] == 1997:
将筛选后df_2021保留成df_1997 以此类推
elif df_2021['WAVE'] == 1997 | df_2021['WAVE'] == 2000:
elif df_2021['WAVE'] == 2000 | df_2021['WAVE'] == 2004:
elif df_2021['WAVE'] == 2004 | df_2021['WAVE'] == 2006:






