
对于如下报错信息的思考理解
Message: stale element reference: element is not attached to the page document
本来打算利用selenium 爬取豆瓣新片榜的是电影信息。
目标网址为 https://movie.douban.com/
在网址上通过find_element_by_xpath方法找到排行榜按钮
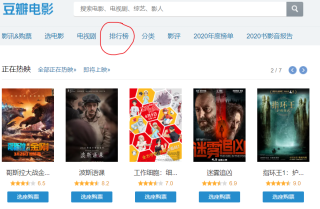
然后用click跳转到排行榜页面,再去获取电影信息,问题出现在click这里。一开始代码如下:
from time import sleep
from selenium import webdriver
url = 'https://movie.douban.com/'
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_id('db-nav-movie')
rank = driver.find_element_by_xpath('.//div[@class="nav-secondary"]/div/ul/li[4]')
rank.click()
print(type(rank))
sleep(1)
rank.find_element_by_id('content')
movies = rank.find_elements_by_xpath('.//div/div[1]/div/div/table')
for i in movies:
print(i.text)
运行报错了
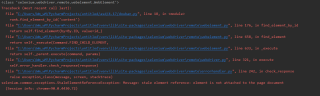
网上查了查大概意思就是找不到这个rank了。并且rank是个webelement类型。
后来不断尝试和测试。不定义rank而是直接用driver跳转,最后成功了。
driver.find_element_by_id('db-nav-movie')
driver.find_element_by_xpath('.//div[@class="nav-secondary"]/div/ul/li[4]').click()
sleep(1)
 最后代码如下:
最后代码如下:
from time import sleep
from selenium import webdriver
url = 'https://movie.douban.com/'
driver = webdriver.Chrome()
driver.get(url)
driver.find_element_by_id('db-nav-movie')
driver.find_element_by_xpath('.//div[@class="nav-secondary"]/div/ul/li[4]').click()
sleep(1)
print(type(driver))
driver.find_element_by_id('content')
movies = driver.find_elements_by_xpath('.//div/div[1]/div/div/table')
for i in movies:
print(i.text)
个人理解:rank是webelement类型,driver是webdriver类型。两个代码都是webelement调用了click(),但是实际跳转任务的“执行者”是webdriver,并且跳到另一个网页之后原网页的webelement就无法使用了。
想要跳回去的话是driver.back()。并且试了试跳回去之后一开始的webelement也是不能用的,所以back就是相当于跳到一个新网站一样。
rank = driver.find_element_by_xpath('.//div[@class="nav-secondary"]/div/ul/li[4]')
print(rank.text)
rank.click()
sleep(1)
driver.back()
print(rank.text)
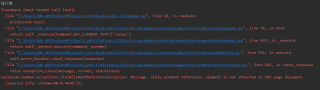
不知道我理解的对不对






