使用Python的scikit-opt包,设计遗传算法,求解以下运输规划问题,数据见excel文档。
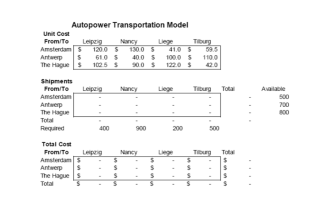

使用Python的scikit-opt包,设计遗传算法,求解以下运输规划问题,数据见excel文档。
 分享
分享
具体可以参考:
import random
import itertools
# import math
import sys
import geatpy
import numpy as np
# gen=50 #进化代数
# n = 9 # 总的仓库数
# m = 3 # 所调用的车的数量
# c = 8 # 车的容量
# pop_size = 20 # 种群大小
# M = 300 # 重惩罚权值
# old_pop_list = [] # 初始父代种群
# distanceMatrix = [] # 两点之间距离
# location=() #初始化仓库位置
# demand = [] #初始化各仓库所需的运货量
# new_pop_list = np.zeros((pop_size, 12)) # 新的种群
# evaluation_list = [] # 每一代中所有染色体的适应度值的列表
# sum_evalution = 0 # 每一代中最大的适应度值
# best_fitness = 0 # 所有代中最好的适应度
# px = 0.6 # 交叉概率
# pm = 0.02 # 变异概率
#生成城市位置的随机坐标
def random_location():
location=[]
n = 9 #8个分仓库与一个总仓库
random_list = list(itertools.product(range(0, 100), range(0, 100))) #product(list1, list2) 依次取出list1中的每1个元素,与list2中的每1个元素,组成元组,
location=random.sample(random_list,n)
return location
# print(location)
#生成随机需求量(分仓库的需求量)
def random_demand():
demand = []
for i in range(8):
random_demand = np.random.uniform(0, 4)
demand.append(round(random_demand, 2))
demand.insert(0,0)
return demand
# demand=random_demand()
# print(demand)
#两仓库之间的计算距离
def distance( ):
location=random_location()
distanceMatrix=np.zeros(shape=(len(location),len(location)))
location=random_location()
# print(distanceMatrix)
for i in range(len(location)):
i -= 1
for j in range(len(location)):
j-=1
if i!=j:
x=location[i][0]-location[j][0]
y=location[i][1]-location[j][1]
distanceMatrix[i][j]=np.sqrt(x * x + y * y)
else:
continue
return distanceMatrix
# distanceMatrix=distance(location)
# print(distanceMatrix)
# 遗传编码(初始化种群)
# 编码生成规则
# 1.生成一个自然数(仓库个数)的全排列
# 2.将m(车辆数)+1个0插入到全排列
# 3.首尾必须是0,且两个0不能相邻
def decode( ):
#生成len(location)-1个初始种群
temp = []
location=random_location()
p_bool = True
p=1
pop_size=20 #种群大小
pop_list=np.empty(shape=[pop_size,12])
for k in np.arange(0,20):
pop = []
temp=random.sample(range(1,len(location)),len(location)-1) #生成随机数
for i in range(len(location)-1):
pop.append(temp[i])
pop.insert(0,0) #在第一位插入0
pop.insert(9,0) #在最后一位插入0
# return pop
#在位置2~9中间插入0,且0不能同时出现在相邻的位置
while p_bool:
p1=random.randint(2,len(location)-2)
p2=random.randint(2,len(location)-2)
p=abs(p1-p2) #判断p1与p2是否相邻
# print("p的值",p)
if p>1: #如果p值大于1则不相邻,符合要求
pop.insert(p1,0)
pop.insert(p2,0)
# print("pop的值",pop)
for j in range(12):
pop_list[k][j] = pop[j]
# print("pop_list的值",pop_list)
break
else:
continue
return pop_list
# print(old_pop_list)
old_pop_list=decode()
#计算适值评价
def caculateFitness(pop, c,M):
current_total = 0.0 # 当前的车的总容量
distance_total = 0.0 # 车的总运行距离
distance_total_list = [] # 每辆车行驶总距离存储列表
evaluation = 0.0 # 评价值
distanceMatrix = distance()
demand = random_demand()
# 根据初始化的种群计算车的行驶路程与车的容量
# 求在pop中0出现的位置列表temp
temp = []
for i in range(0, len(pop)):
j = pop[i]
if j == 0:
temp.append(i)
# 计算每辆车总行驶的距离,与离开每个仓库时,车上装运的货物的总容量
#如果到达某一个仓库时
for i in np.arange(0, len(temp)-1):
interm_list = np.arange(temp[i], temp[i + 1])
for k in interm_list:
# print("控制循环的k", k)
j = int(pop[k])
i = int(pop[k + 1]) #必须加int,否则报错only integers, slices (`:`), ellipsis (`...`)
if j == 0:
distance_total += distanceMatrix[i][0]
current_total += demand[j]
if current_total > c:
distance_total += M*abs(current_total-c)
# print("j=", j, distance_total,"目前总容量",current_total)
else:
distance_total += distanceMatrix[i][j]
current_total += demand[j]
if current_total > c:
distance_total +=M*abs(current_total-c)
# print("i", i, distance_total,"目前总容量",current_total)
evaluation += distance_total
distance_total = 0
current_total = 0
return 10/evaluation #evalution代表的时运输成本的评估值,应该是越小越好,因此此地返回一个evalution的倒数
#计算初始单个染色体的评价值,与总体的评价值,为染色体选择做准备
def sum_evalution(old_pop_list,c,M):
evaluation_list=[]
sum_evalution = 0
old_pop_list=old_pop_list
for i in range(20):
# print("=============================第%s个种种群===============================" %(i))
pop = old_pop_list[i]
evaluation= 0.0
evaluation = caculateFitness(pop,c,M) #单个的evalution
evaluation_list.append(evaluation)
# print("单个的evalution", evaluation)
sum_evalution += evaluation #整个种群的sum_evalution
# print("整个种群的sum_evalution", sum_evalution)
return (evaluation_list,sum_evalution)
# location = random_location() #仓库位置
# demand = random_demand() #仓库所需的运货量
# distanceMatrix = distance( ) #两点之间距离
# old_pop_list = decode( ) #遗传编码
# print(sum_evalution(old_pop_list))
# # print(sum_evalution( ))
# # evaluation_list = sum_evalution( )[0]
# # sum_evalution=sum_evalution( )[1]
# print("evaluation_list",evaluation_list,"sum_evalution",sum_evalution)
# # print("evaluation_list",evaluation_list)
#求适值函数,各个个体累计概率
def evalution_function(evaluation_list,sum_evalution):
f=[]
g=[]
for i in np.arange(0,20):
if i == 0:
g.append(evaluation_list[i] / sum_evalution)
# print("个体%s的累计概率"%i,g)
f.append(g[i])
else:
g.append((evaluation_list[i]/sum_evalution)+g[i-1])
f.append(g[i])
# print("个体%s的累计概率"%i,"f的值",f)
# print("===========================")
# g.append((evaluation_list[i] / sum_evalution)+evaluation_list[i-1])
# print("个体%s的累计概率"%i,"g的值",g)
return f
# function=evalution_function(evaluation_list,sum_evalution)
# print(function[0],function)
# print("各个个体累计概率",evalution_function(evaluation_list,sum_evalution))
#选择种群中适应度最高的,也就是函数caculateFitness返回值最大的,既def sum_evalution( )中返回的evaluation_list中最大的
#选择种群中适应度最高,最高适应度对应的下标
def maxevalution(evaluation_list):
max_fitness=0.0 #每一代种群中的最大适应度
max_id=0 #每个种群中最大的适应度所对应的下标
for i in np.arange(0,20):
if max_fitness > evaluation_list[i]:
continue
else:
if max_fitness < evaluation_list[i]:
max_fitness=evaluation_list[i]
max_id=i
return (max_fitness,max_id)
# max_fitness = maxevalution(evaluation_list)[0]
# max_id = maxevalution(evaluation_list)[1]
# print(maxevalution(evaluation_list))
#染色体复制,从old_pop_list中将挑选的染色体复制到新的new_pop_list中
def copypop(new_pop_list, old_pop_list,new_id,old_id):
old_id=old_id #父代中最大的适应度所对应的下标
new_l=new_id #新的种群的位置
for i in np.arange(0,12):
new_pop_list[new_l][i]=old_pop_list[old_id][i]
return new_pop_list
#在[0,1]之间的生成一个随机数
def randomFinger(old_pop_list,c,M):
x = 0.0
a=0
evalution_list = sum_evalution(old_pop_list, c, M)[0]
# print(evalution_list)
sum_e = sum_evalution(old_pop_list, c, M)[1]
function = evalution_function(evalution_list, sum_e)
a=function[11]
print(a)
for i in range(1):
x = np.random.uniform(0,a)
return x
# x=0.0
# x=randomFinger(old_pop_list,8,3)
# print(x)
#进化函数,保留最优
def evalutionFunction(new_pop_list,old_pop_list, evaluation_list,function):
#找出最大适应度的染色体,把他放到新的种群第一个,既子代的第一个。
c=8
M=3
max_id = maxevalution(evaluation_list)[1]
new_pop_list = copypop(new_pop_list, old_pop_list, 0, max_id)
# print("父代中适应度最高的进入子代形成的new_pop_list",new_pop_list)
#赌轮选择策略挑选scale-1个下一代个体
k=0
for i in np.arange(1,20):
x = randomFinger(old_pop_list,c,M)
# print("产生的随机数",x)
# print("控制循环的I", i)
for j in np.arange(20):
# print("function",function[j])
if j == 0:
if x < function[0]:
new_pop_list= copypop(new_pop_list, old_pop_list, i,0)
# print("判断轮盘赌第一个是否能进入",new_pop_list)
# break
else:
if j !=0:
if x < function[j] and x > function[j-1]:
new_pop_list = copypop(new_pop_list, old_pop_list,i, j)
# print("判断进入的先后顺序%d"%j,new_pop_list)
# break
return new_pop_list
# new_pop_list= evalutionFunction(new_pop_list ,evaluation_list,function)
# print(new_pop_list)
#交叉和变异
# new_pop_list=geatpy.xovpm(new_pop_list,px)
# print(new_pop_list)
# FieldDR=np.array([[0,0,0,0,0,0,0,0,0,0,0,0],
# [8,8,8,8,8,8,8,8,8,8,8,8]])
# new_pop_list=geatpy.mutbga(new_pop_list,FieldDR, pm).astype(np.int)
# print(new_pop_list)
#整理染色体,使其满足要求
def sort_pop(new_pop_list):
print("传入的new_pop_list", new_pop_list)
for i in np.arange(20):
pop=new_pop_list[i]
print("传入的pop",pop)
# 求在pop中0出现的位置列表temp
temp = []
for k in np.arange(0, len(pop)):
j = pop[k]
if j == 0:
temp.append(k)
# print("temp的值",temp)
#经过变异后可能头尾不再是0,变成0
if pop[0] !=0 or pop[11]!=0:
pop[0] = 0
pop[11] = 0
#再重新计算0的个数
temp=[]
for k in np.arange(0, len(pop)):
j = pop[k]
if j == 0:
temp.append(k)
#当0的个数大于4 时,说明缺失了某一个1~8的数,补上
d=len(temp)
k=1
if d > 4:
for i in np.arange(1,9):
if i not in pop:
p = temp[k]
# print("%d在数组内"%i)
pop[p] = i
k+=1
# else:
# print("%d不在数组内" % i)
分享



