
老哥们,新人入坑,在用requests抓取页面中的图片,主要是想批量下载练练手,下面这张是页面源码:
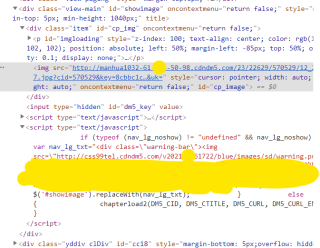
但是我爬取完之后显示id为“cp_img”的div标签内的内容为:
![]()
以下是我的测试代码,主要是想抓到那个id为cp_img的div里面的内容:
import requests as rq
from bs4 import BeautifulSoup as bf
if __name__ == "__main__":
url = 'http://www.1kkk.com/ch66-570484-p2/'
myheaders = {
'User-Agent':'Mozilla/5.0',
'Referer':'http://www.1kkk.com/ch66-570484-p2/'
}
res = rq.get(url=url,headers=myheaders)
res.encoding = 'utf-8'
con = res.text
bf1 = bf(con,'lxml')
with open('file.html','w') as fp:
fp.write(bf1.prettify())
fp.close
imgs = bf1.find_all('div',id='cp_img')
print(imgs)
也查了很多,有说div折叠的,有说动态加载的,但是当时我用chrome抓到的包里也没有目的图片啊
求解





