

3.用汉语输入两句话,统计其中出现各种词语的次数。 (给出源程序代码并截图运行结果)



2条回答 默认 最新
 CSDN专家-HGJ 2021-05-17 02:03关注
CSDN专家-HGJ 2021-05-17 02:03关注用jieba进行分词,用collections的Counter进行计数,代码及运行结果:
import jieba import string from collections import Counter inp1=input('输入第一句汉语:') inp2 = input('输入第二句汉语:') inp=inp1+inp2 all_punc = string.punctuation+',。、【 】 “”:;()《》‘’{}?!⑦()、%^>℃:.”“^-——=&#@¥' words=jieba.cut(inp) word_num=Counter([w for w in words if w not in all_punc]) result =sorted(word_num.items(), key=lambda x: x[1], reverse=True) print(result)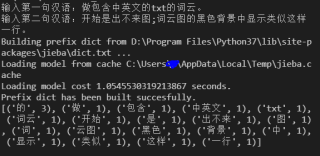 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2021-05-16 23:30回答 2 已采纳 用jieba进行分词,用collections的Counter进行计数,代码及运行结果: import jieba import string from collections import Co
- 2022-08-11 20:23回答 4 已采纳 感谢各位,已经解决了,在隔壁帖子找到了解决方法https://blog.csdn.net/national_/article/details/121594916
- 2022-10-22 23:02回答 1 已采纳 首先可以在网上下一个停用词文本:hit_stopwords.txt,然后将你的文章写到一个文本文件“文章.txt”中,代码如下: from collections import Counter imp
- 2022-09-23 18:33jieba分词功能在python中的实现方法
- 2022-04-16 15:04回答 1 已采纳 文件这样读取:text = open('......txt', encoding = 'UTF-8').read() 这篇文章可以看看,如有用请采纳 https://blog.csdn.net/w
- 2022-01-20 15:42回答 2 已采纳 看出来了, 你不要用和库名一样的文件名 把程序名改为 myjieba.py
- 2022-04-16 13:42回答 2 已采纳 可以参考一下 OSError: cannot open resource 错误原因及解决方法_陆离_的博客-CSDN博客_cannot open resource
- 2020-12-30 19:24import jieba def replaceSynonymWords(string1): # 1读取同义词表,并生成一个字典。 combine_dict = {} # synonymWords.txt是同义词表,每行是一系列同义词,用空格分割 for line in open(TihuanWords.txt, r,...
- 2022-06-02 11:36回答 1 已采纳 代码没错,只是你输出的内容错了可以参考 jieba.cut与jieba.lcut的区别_blackieliu的博客-CSDN博客_jieba.cut
- 2023-02-23 13:36回答 3 已采纳 该回答引用GPTᴼᴾᴱᴺᴬᴵ根据错误信息来看,可能是网络连接问题导致下载失败。你可以尝试使用 VPN 或者等待一段时间后再次尝试下载安装。另外,你也可以通过其他渠道下载安装包,然后通过 pip 命令安
- 2022-06-23 10:48回答 2 已采纳 找不到文件,你现在应该使用的是相对路径的写法,保证txt文件和运行的脚本文件在同一目录下。文件名也用复制的方式,避免出错。有帮助请采纳,还有不懂的可以继续追问~
- 2020-12-23 21:27用jieba和wordcloud两个强大的第三方库,就可以轻松打造出x云漏洞词云。 github地址: https://github.com/theLSA/wooyun_wordcloud 本站下载地址:wooyun_wordcloud 0x01 爬取标题 直接上代码: #coding:utf-8 #...
- 2023-06-25 09:53陌北v1的博客 本教程介绍了Python中jieba库的基本使用方法和常用功能,包括分词基础、自定义词典、关键词提取、词性标注、并行分词和Tokenize接口。通过学习和掌握这些功能,你可以在中文文本处理中灵活应用jieba库,实现有效的...
- 2022-03-25 19:35SteveKenny的博客 文章目录jieba库一、 简介1、 是什么2、 安装二、 基本使用1、 三种模式2、 使用语法2.1 对词组的基本操作2.2 关键字提取2.3 词性标注2.4 返回词语在原文的起止位置 jieba库 一、 简介 1、 是什么 (1)jieba是优秀...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 这是哪个作者做的宝宝起名网站
- ¥60 版本过低apk如何修改可以兼容新的安卓系统
- ¥25 由IPR导致的DRIVER_POWER_STATE_FAILURE蓝屏
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!