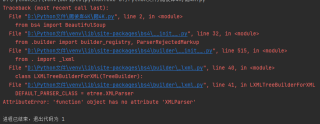
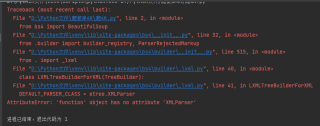
python小白,在网上复制的python爬虫代码,在自己电脑上运行会报错。
感谢大神能看我的问题,希望能帮忙解答一下,谢谢。
代码如下:
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
import os
#分析网页
def fx(target):
req = requests.get(url=target)
req.encoding = 'gb18030'
html = req.text
bs = BeautifulSoup(html, 'lxml')
return bs
#获取模版首页所有分类,创建文件夹
def category(target):
texts = fx(target).find('div', class_='classify clearfix')
texts = texts.find_all('a')
for text in texts:
url = text.get('href')
title = text.string
categoryurl = 'http://pic.netbian.com'+url
os.mkdir(title) #创建文件夹
path = './' + title + '/' #分类下载路径
print(title)
#print(listurl)
downpic(categoryurl, path)#下载列表首页
listpage(categoryurl,path)#下载剩余列表
#获取每个类别所有页面
def listpage(target,path):
path1 = path
try:
texts = fx(target).find('div', class_='page')
texts = texts.find_all('a')
#获取每页url
str1 = texts[-2].string
listpage = int(str1)
for i in range(1, listpage):
listpage1 = str(i+1)
listurl = target + 'index_' + listpage1 + '.html'
downpic(listurl,path1) #下载分类中所有页
except:
pass
#下载图片
def downpic(target, path):
path1= path
texts = fx(target).find('ul', class_='clearfix')
texts = texts.find_all('a')
for text in tqdm(texts):
url = 'http://pic.netbian.com'+ text.get('href')
title = text.find('b').string
url1 = 'http://pic.netbian.com' + fx(url).find('a', id='img').find('img').get('src')
try:
r = requests.get(url1)
with open(path1 + title + '.jpg', 'wb') as code:
code.write(r.content)
except:
pass
if __name__== '__main__':
target = 'http://pic.netbian.com/'
category(target)