收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
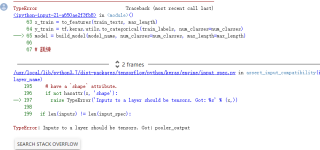
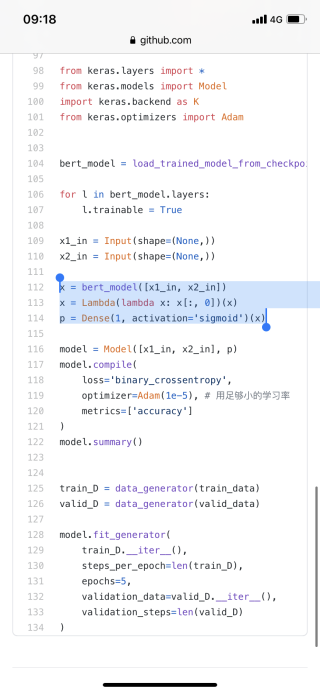
可以参考一下这个
https://github.com/bojone/bert_in_keras/blob/master/sentiment.py
报告相同问题?