关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
BIU 变
2021-06-12 23:04
采纳率: 100%
浏览 52
首页
大数据
已采纳
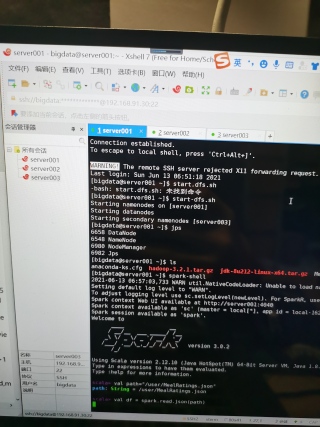
Xshell成功连接虚拟机启动spark之后执行很慢,是我电脑问题吗
spark
有问必答
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN专家-微编程
2021-06-13 01:36
关注
主要有两个原因,第一个就是你的电脑本身就不好,配置低,第二个就是你给这个虚拟机分配的运行内存不够或者说有点小了
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
spark
和scala环境安装与部署(超详细版),我保证你敢看,你就学会了
2024-03-08 13:15
大数据三班罗健的博客
是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架
Spark
得到了众多
大数据
公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里...
大数据
概论
2022-09-05 21:27
zjh0101的博客
大数据
概轮
大数据
常见运维
问题
汇总
2021-03-16 20:05
GoAI的博客
大数据
常见运维
问题
汇总 其他安装
问题
: 1.IDEA安装与配置 https://blog.csdn.net/qq_27093465/article/details/77449117 2.IntelliJ IDEA 修改maven为阿里云仓库 ...
Hadoop生态圈
大数据
文档
2021-12-01 09:45
BigData_XiaoBai的博客
文档基于介绍基于Hadoop的
大数据
生态圈。介绍下图每一个组件的使用场景及使用方法,同时还对每一个组件有更深入的介绍。 ...
大数据
项目之电商数据仓库系统回顾
2023-04-08 17:08
三月枫火的博客
大数据
项目之电商数据仓库系统
大数据
-数据仓库(原理+实战)
2024-07-24 12:24
玉骨.的博客
ETL 这个部分占比60%-80%,
之后
数据进入ODS里 数据抽取 不同数据: 结构化——JDBC:
很慢
,IO
问题
,这种会选择在凌晨,有业务甚至不允许 结构化——数据库日志,直接采,不走IO 对于非/半结构——监听文件变动 更新...
从0开始搭建分布式Hadoop+
Spark
+Flink+Hbase+Kafka+Hive+Flume+Zookeeper+Mysql等
2024-09-18 20:32
菜鸡上山打老虎的博客
从0开始搭建分布式Hadoop+
Spark
+Flink+Hbase+Kafka+Hive+Flume+Zookeeper+Mysql等
大数据
技术之Hadoop概述集群环境搭建常见错误解决等
2022-11-03 23:54
YuanZhi.w的博客
集群配置 群起集群 配置历史服务器 配置日志的聚集 集群
启动
/停止方式总结 编写Hadoop集群常用脚本 常用端口号说明 集群时间同步(注意:如果能
连接
外网则可直接省略) 常见错误及解决方案 1. Hadoop是什么 ① Hadoop...
【
大数据
】Hadoop—— 三大核心组件理论入门 | 完全分布式集群搭建 | 入门项目实战
2022-08-31 16:43
亦梦亦醒乐逍遥的博客
不过这一个礼拜感觉很轻松,再好不过了,可惜的是老师因为录音设备的
问题
,在线上课的效果非常差,所以我找了一个很不错的慕课听。有趣的是,这个慕课和老师讲的基本重合,甚至老师要讲什么我都能猜出来,我都有点...
分布式
大数据
环境搭建教程
2017-12-20 15:48
她说巷尾的樱花开了的博客
在安装过程中会遇到很多linux命令,在此对重要命令进行总结 (1):VMware
虚拟机
与Windows间系统光标切换快捷键:Ctrl+Alt (2):linux系统复制快捷键:Ctrl+Insert (3):linux系统粘贴快捷键是:Shift+Insert ...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享


