- 请发现自身、同学朋友或父母亲戚的日常学习、工作或生活中的“重复性劳动”,尝试“制造工具”帮助解决问题。

 分享
分享
python自动化办公:word篇。职场高手不是梦:https://blog.csdn.net/kobeyu652453/article/details/107638171
python自动化办公:excel篇,从此做表不加班:https://blog.csdn.net/kobeyu652453/article/details/107578299
实例:
工具包安装
使用的库:docx
python 没有自带。需要安装。
若运行出现:ModuleNotFoundError: No module named ‘exceptions’
则说明安装失败,需要另外安装
安装方法
先卸载之前安装失败的docx
1、下载 python_docx-0.8.6-py2.py3-none-any.whl 地址: http://www.lfd.uci.edu/~gohlke/pythonlibs/
2、在这个网页的最下边有python_docx-0.8.6-py2.py3-none-any.whl这个安装包,可以CRTL+F 查一下python这个关键字
3、将下载好的.whl文件放到你的工程目录下
4、进入工程目录下, 命令行输入pip install python_docx-0.8.6-py2.py3-none-any.whl 重新下载docx包,问题解决。
如图 我的anaconda cmd 工程目录是 C:\Users\Shineion

任务场景1

开始编写
业务逻辑
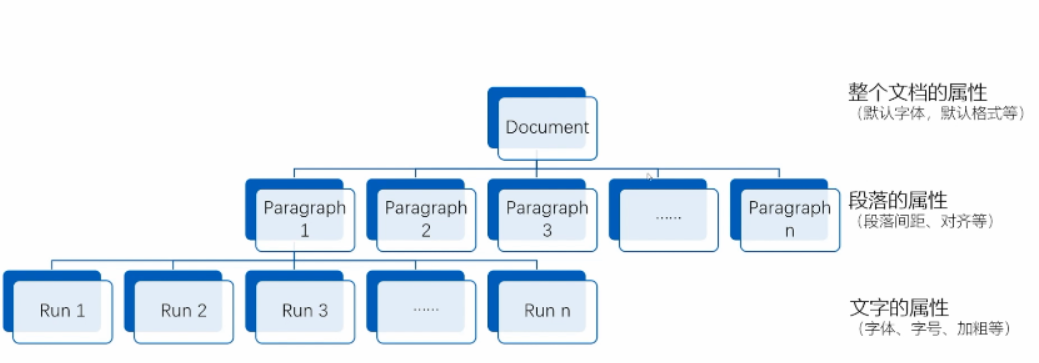
Document 文档
Pargraph段落
run 句子

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT#对齐方式
from docx.shared import Pt#磅数
from docx.oxml .ns import qn #中文格式
import time
price=input("请输入今日价格:")
company_list=['客户1','客户2','客户3','客户4','客户5','客户6','客户7','客户8','客户9']
today=time.strftime('%Y{Y}%m{m}%d{d}',time.localtime()).format(Y='年',m='月',d='日')#把今日事件整理成2020-07-28 %Y %m %d 不能动。-可以变
for i in company_list:
document=Document()#新建一个文档
#对整个文档设置字体
document.styles['Normal'].font.name=u'宋体'# styles['Normal']默认样式
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'),u'宋体')#设置中文字体,这款软件非国人开发,对中文支持差,所以需要这行。
#设置文档的基础字体
p1=document.add_paragraph()#加初始化第一个自然段
p1.alignment=WD_PARAGRAPH_ALIGNMENT.CENTER#居中对齐,默认左对齐
run1=p1.add_run('关于下达%s产品价格的通知'%(today))#添加内容
run1.font.name='微软雅黑'#设置标题字体
run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')#设置中文格式
run1.font.size=Pt(21)#设置标题字大小
run1.font.bold=True#标题加粗
run1.space_after=Pt(5)#段后距离5磅
run1.space_before=Pt(5)#距离段前距离5磅
#第二段 客户称呼
p2 = document.add_paragraph() # 加初始化第二个自然段
run2=p2.add_run(i+": ")#客户称呼
run2.font.name='仿宋_GB2312'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run2.font.size = Pt(15) # 设置字大小
run2.font.bold = True # 加粗
#第三段 正文
p3 = document.add_paragraph() # 加初始化第三个自然段
run3 = p3.add_run(' 根据公式安排,为提供石油优质客户服务,我单位拟定今日石油价格为%s元,特此通知。'%(price)) # 正文
run3.font.name = '仿宋_GB2312'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run3.font.size = Pt(15) # 设置字大小
run3.font.bold = True # 加粗
#第四段 联系方式
p4 = document.add_paragraph() # 加初始化第四个自然段
p4.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐,默认左对齐
run4=p4.add_run('联系人:余总 电话:1999999999')
run4.font.name = '仿宋_GB2312'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run4.font.size = Pt(15) # 设置字大小
run4.font.bold = True # 加粗
document.save(r'C:\Users\Shineion\Desktop\测试\%s-价格通知.docx'% i)#使用 客户名+价格通知 命名
结果文件夹
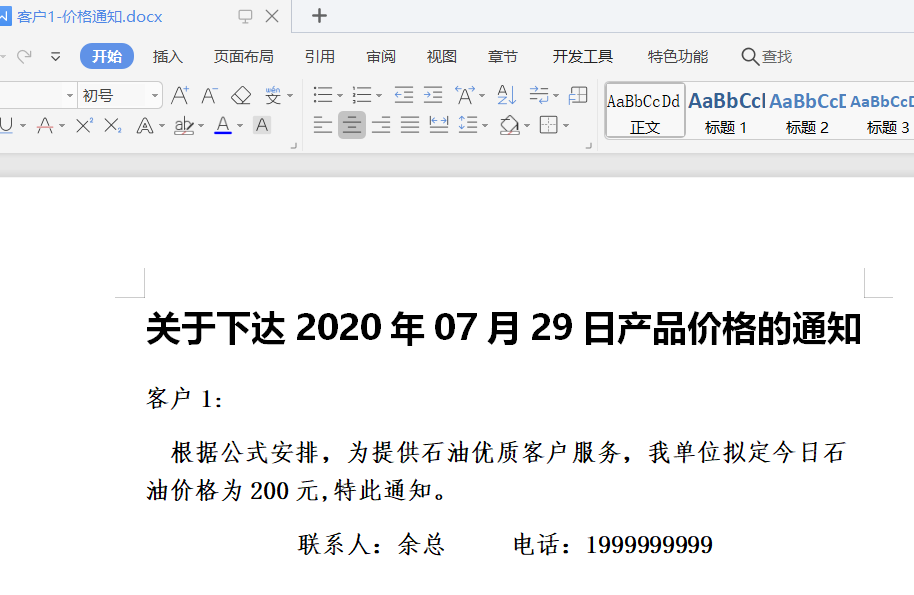
在文档中插入图片和表格

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT#对齐方式
from docx.shared import Pt#磅数
from docx.oxml .ns import qn #中文格式
from docx.shared import Inches#修改图片尺寸
import time
price=input("请输入今日价格:")
company_list=['客户1','客户2','客户3','客户4','客户5','客户6','客户7','客户8','客户9']
today=time.strftime('%Y{Y}%m{m}%d{d}',time.localtime()).format(Y='年',m='月',d='日')#把今日事件整理成2020-07-28 %Y %m %d 不能动。-可以变
for i in company_list:
document = Document() # 新建一个文档
# 对整个文档设置字体
document.styles['Normal'].font.name = u'微软雅黑' # styles['Normal']默认样式
document.styles['Normal'].font.size=Pt(14)
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑') # 设置中文字体,这款软件非国人开发,对中文支持差,所以需要这行。
# 设置文档的基础字体
#加载图片,并修改尺寸
document.add_picture('图片红头.png',width=Inches(6))
#第一段内容
p1 = document.add_paragraph() # 加初始化第一个自然段
p1.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐,默认左对齐
run1 = p1.add_run('关于下达%s产品价格的通知' % (today)) # 添加内容
run1.font.name = '微软雅黑' # 设置标题字体
run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑') # 设置中文格式
run1.font.size = Pt(21) # 设置标题字大小
run1.font.bold = True # 标题加粗
run1.space_after = Pt(5) # 段后距离5磅
run1.space_before = Pt(5) # 距离段前距离5磅
#第二段
# 第二段 客户称呼
p2 = document.add_paragraph() # 加初始化第二个自然段
run2 = p2.add_run(i + ": ") # 客户称呼
run2.font.name = '仿宋_GB2312'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run2.font.size = Pt(15) # 设置字大小
run2.font.bold = True # 加粗
# 第三段 正文
p3 = document.add_paragraph() # 加初始化第三个自然段
run3 = p3.add_run(' 根据公式安排,为提供优质客户服务,我单位拟定今日价格如下:。') # 正文
run3.font.name = '仿宋_GB2312'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run3.font.size = Pt(15) # 设置字大小
run3.font.bold = True # 加粗
#添加表格
table=document.add_table(rows=3,cols=3,style='Table Grid')#初始化表格,style为格式,自己查
table.cell(0,0).merge(table.cell(0,2))#合共单元格,从(0,0) 合共到(0,2) 即第一行合并。选择左上和右下两格位置即可合并
table_run1=table.cell(0,0).paragraphs[0].add_run('xx产品报价表')#paragraphs[0]这个段落是在表格里面
table_run1.font.name=u'宋体'
table_run1.element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') # 设置中文格式
table.cell(0, 0).paragraphs[0].alignment=WD_PARAGRAPH_ALIGNMENT.CENTER#第一行居中
#使用表格默认字体格式来添加内容
table.cell(1,0).text='日期'
table.cell(1, 1).text = '价格'
table.cell(1, 2).text = '备注'
table.cell(2, 0).text = today
table.cell(2, 1).text = str(price)
table.cell(2, 2).text = ' '
# 第四段 联系方式
p4 = document.add_paragraph() # 加初始化第四个自然段
p4.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 居中对齐,默认左对齐
run4 = p4.add_run('联系人:余总 电话:1999999999')
run4.font.name = '仿宋_GB2312'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312') # 设置中文格式
run4.font.size = Pt(15) # 设置字大小
run4.font.bold = True # 加粗
#插入分页符 ,然后在第二页插入广告
document.add_page_break()#插入分页符
p5 = document.add_paragraph() # 加初始化第五个自然段
run5=p5.add_run('广告所在地')
document.save(r'C:\Users\Shineion\Desktop\测试\%s-价格通知.docx' % i) # 使用 客户名+价格通知 命名
第一页
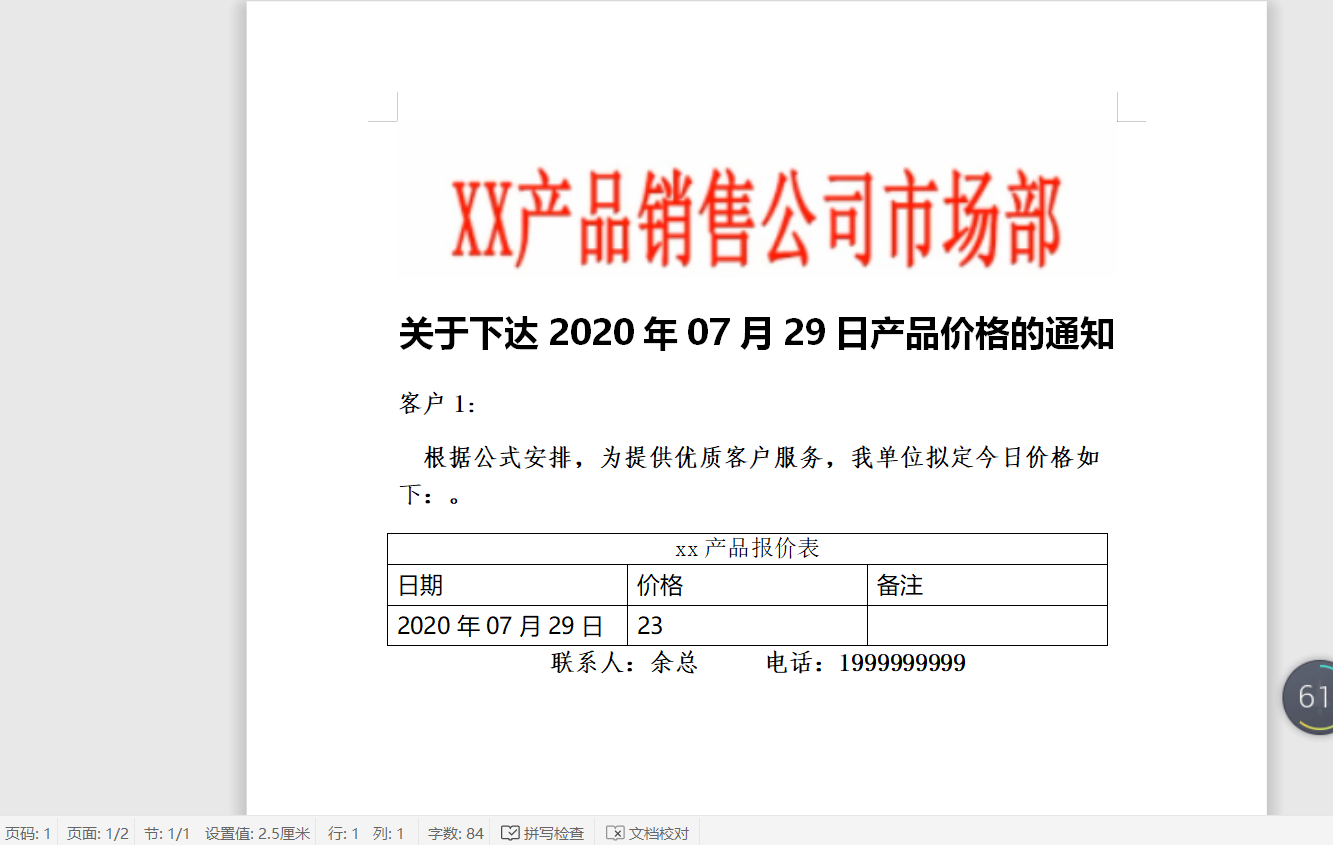
第二页

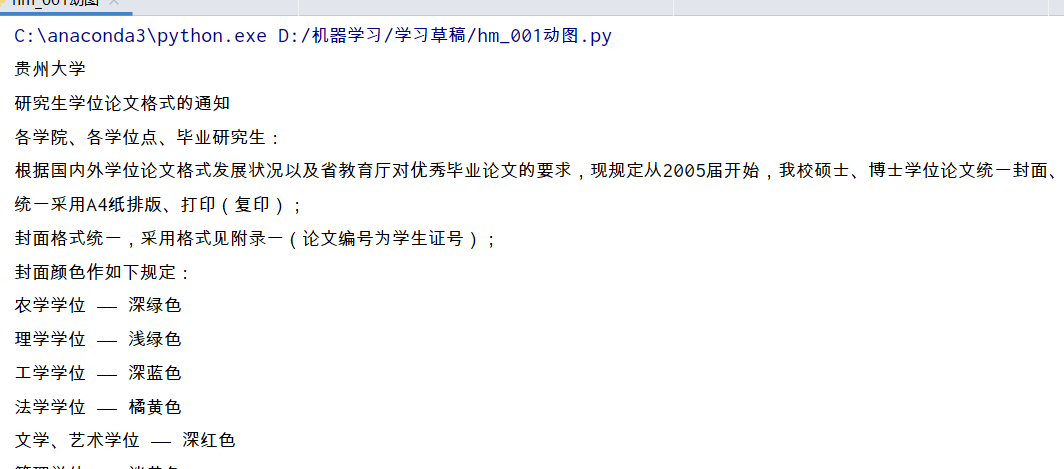
从word文档中读取内容
读取内容
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
document=Document(r'C:\Users\Shineion\Desktop\新建 DOCX 文档.docx')#文件路径 文件格式为docx。 doc要出错,问题我不清楚
all_paragraphs=document.paragraphs#所有段落
for paragraph in all_paragraphs:
print(paragraph.text)
#不要使用下面的,因为一个段落里可能有多个run,这样会打乱,人很难读
#for run in paragraph.runs:
#print(run.text)
读取Word表格里的内容
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
document=Document(r'C:\Users\Shineion\Desktop\新建 DOCX 文档.docx')#文件路径 文件格式为docx。 doc要出错,问题我不清楚
all_tables=document.tables#获取所有表格
for table in all_tables:
for row in table.rows:#每一行
for cell in row.cells:#获取单元格
print(cell.text)
原文文件:

结果:

读取含有文字和表格的Word

# @Author: yudengwu
import zipfile
word=zipfile.ZipFile(r'C:\Users\Shineion\Desktop\新建 DOCX 文档.docx')
xml=word.read("word/document.xml").decode('utf-8')#读取文档前端页面内容
发现存在文字的部分 前面有<w:t> 这个符号

以<w:t> 分割字符
xml_list=xml.split('<w:t>')
以下为正则方法提取文本
正则教程
python :re模块基本用法
text_list=[]
for i in xml_list:
if i.find('</w:t>')+1:#i.find('<w:t>')值为1和-1,-1为没找到。+1是为了变成0和正数,即true,false
text_list.append(i[:i.find('</w:t>')])
else:
pass
print(text_list)
text="".join(text_list)
print(text)
所有代码;
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
import zipfile
word=zipfile.ZipFile(r'C:\Users\Shineion\Desktop\新建 DOCX 文档.docx')
xml=word.read("word/document.xml").decode('utf-8')#读取文档前端页面内容
xml_list=xml.split('<w:t>')
text_list=[]
for i in xml_list:
if i.find('</w:t>')+1:#i.find('<w:t>')值为1和-1,-1为没找到。+1是为了变成0和正数,即true,false
text_list.append(i[:i.find('</w:t>')])
else:
pass
print(text_list)

word格式套用:创造模板
适合快速写短文档
#传统的做法是一段段设置段落,add_run等,如果段落较多,设置一个函数 即创造一个模板
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT#对齐方式
from docx.shared import Pt#磅数
from docx.oxml .ns import qn #中文格式
#传统的做法是一段段设置段落,add_run等,如果段落较多,设置一个函数
list=['余总的女朋友','余总的媳妇']
for change in list:
document = Document() # 新建一个文档
# 对整个文档设置默认字体格式
document.styles['Normal'].font.name = u'黑体' # styles['Normal']默认样式
document.styles['Normal'].font.size = Pt(14)
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'黑体') # 设置中文字体,这款软
def add_context(context):
p = document.add_paragraph() # 初始化一个段落
p.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT # 左对齐
r = p.add_run(str(context)) # 添加文本
r.font_size = Pt(16)
p.space_after = Pt(5) # 段后距离
p.space_before = Pt(5) # 段前距离
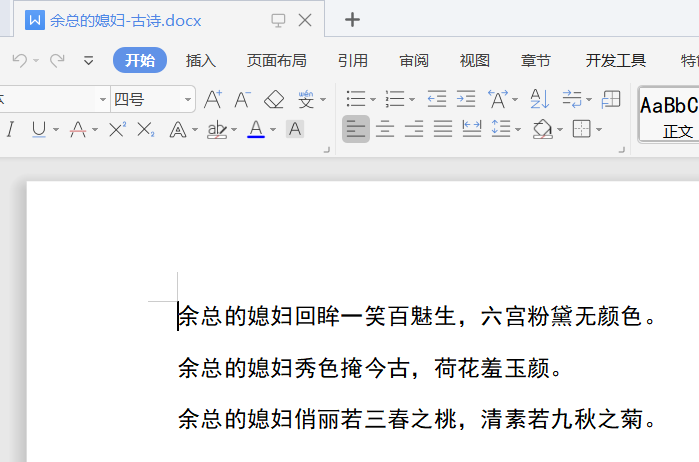
add_context('%s回眸一笑百魅生,六宫粉黛无颜色。' % change)#在段首添加文字
add_context('%s秀色掩今古,荷花羞玉颜。' % change)#在段首添加文字
add_context('%s俏丽若三春之桃,清素若九秋之菊。' % change)#在段首添加文字
document.save(r'C:\Users\Shineion\Desktop\测试\%s-古诗.docx' % change)#保存,文件路径
我只写啦三段内容。
结果:
word格式套用:套用模板
适合快速写长的文档,
自己可以先在word里做好模板,
因此不再需要再代码定义文档格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu
from docx import Document#负责文档
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT#对齐方式
from docx.shared import Pt#磅数
from docx.oxml .ns import qn #中文格式
#导入一个现成的word文档模板
document=Document(r'C:\Users\Shineion\Desktop\新建 DOCX 文档.docx')#使用docx文档吧,doc好像要保错
#替换文字
def change(old_text,new_text):
all_paragraphs = document.paragraphs # 所有段落
for paragraph in all_paragraphs:
#前文介绍了读取所有内容,如果在paragraph层替换会丢弃格式,所以选择run层
# 定义到run层,如果结果很乱,需要将原始文档以纯文字形式复制到另一个文档,将另一个文档作为模板.粘贴方式选择只保留文本
for run in paragraph.runs:
run_text=run.text.replace(old_text,new_text)#替换
run.text=run_text
#如果有表格
"""
all_tables = document.tables # 获取所有表格
for table in all_tables:
for row in table.rows: # 每一行
for cell in row.cells: # 获取单元格
cell_text=cell.text.replace(old_text,new_text)
cell.text=cell_text
"""
#文字替换
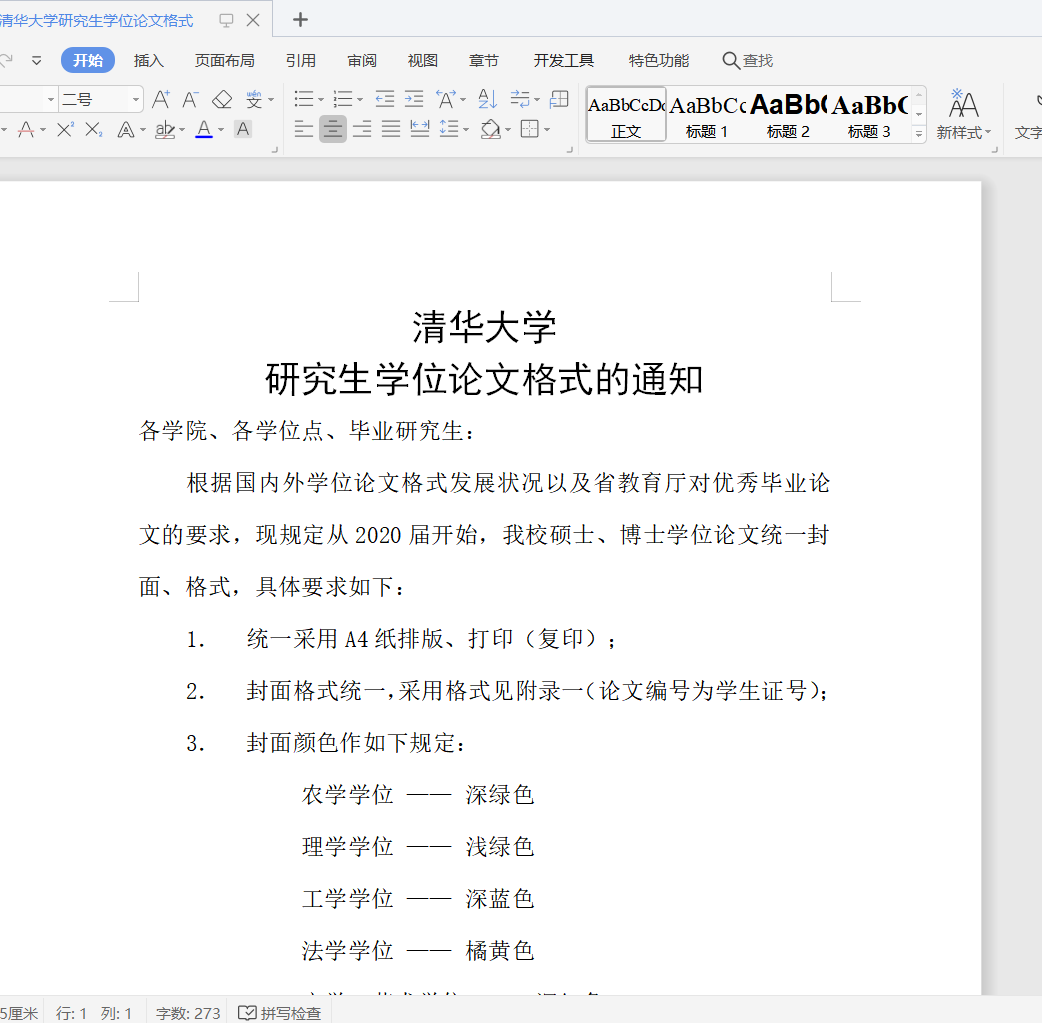
change('贵州大学','清华大学')
change('2005','2020')
change('2004','2020')
i='清华大学研究生学位论文格式'
document.save(r'C:\Users\Shineion\Desktop\测试\%s.docx'%i)
原始文件 暴露学校啦。
博主没本事,读不了名校。

结果:
Word转PDF
她来啦
使用的库 win32com
安装指令 pip install pywin32
遍历一个文件夹,将文件夹的word文档全转换成PDF
这段代码有借鉴他人
from win32com.client import Dispatch
from os import walk
wdFormatPDF = 17
def doc2pdf(input_file):
word = Dispatch('Word.Application')
doc = word.Documents.Open(input_file)
doc.SaveAs(input_file.replace(".docx", ".pdf"), FileFormat=wdFormatPDF)
doc.Close()
word.Quit()
if __name__ == "__main__":
doc_files = []
directory = "C:\Users\Shineion\Desktop\测试"
for root, dirs, filenames in walk(directory):
for file in filenames:
if file.endswith(".doc") or file.endswith(".docx"):
doc2pdf(str(root + "\\" + file))
分享




