

给定2个csv文件 score.csv zhiwu.csv

(1) score对象新增一列“总分”,值为前三列成绩之和。
(2) score对象依据“总分”列的值从高到低进行排序。
(3) score对象根据“性别”列进行分组,输出男生、女生各自的平均成绩。
(4) 输出男生的最高总分、女生的最低总分。
(5) score对象新增一列“等级”,总分大于等于270的等级为A,总分小于210分的等级为C,总分介于210到270的等级为B。
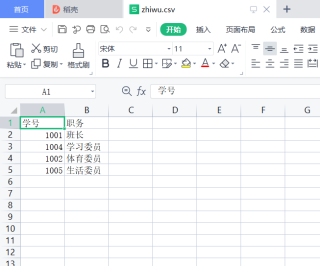
(6) 使用merge()函数以“学号”列为关键主键,将score对象与zhiwu对象合并,合并时保留score对象的所有数据行,合并后生成一个新的DataFrame对象students。以students的“学号”列作为新索引,打印输出students。





