

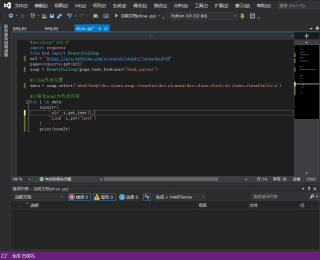
#encoding='utf-8'
import requests
from bs4 import BeautifulSoup
url = 'https://pic.netbian.com/e/search/result/?searchid=49'
page=requests.get(url)
soup = BeautifulSoup(page.text,features="html.parser")
#//dom节点位置
data = soup.select('html>body>div.class.wrap clearfix>div.id.main>div.class.slist>ul.class.clearfix>li>a')
#//转化html为节点内容
for i in data:
result={
'alt':i.get_text(),
'link':i.get('href')
}
print(result)
我看不懂这段代码,求解释





