



3条回答 默认 最新
 CSDN专家-天际的海浪 2021-07-01 20:23关注
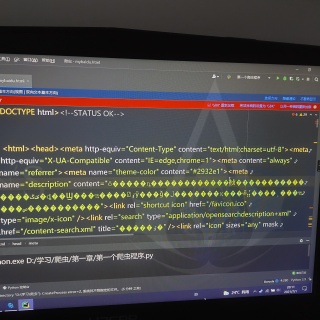
CSDN专家-天际的海浪 2021-07-01 20:23关注获取requests.get()请求数据之后要先用 res.encoding='utf-8' 设置内容的编码再取 res.text 内容
res=requests.get(f'http://www.xxxxxxxx',headers=head) res.encoding='utf-8' html = res.text本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2021-07-01 20:13回答 3 已采纳 获取requests.get()请求数据之后要先用 res.encoding='utf-8' 设置内容的编码再取 res.text 内容 res=requests.get(f'http://www.x
- 2022-04-29 10:30回答 1 已采纳 需要在浏览器上临时显示后端实时处理的图像,需要将图像数据转成json字符串传输给js绘图。 后端python处理: import cv2 as cvfrom encodings import base
- 2022-04-07 11:17回答 3 已采纳 w改为a(追加),要不会将当前写入的内容覆盖文件内容 要么将open和close放到for循环外
- 2022-07-20 11:20这般女子的博客 python爬取网页数据出现中文乱码解决办法
- 2021-08-08 11:16回答 2 已采纳 你只是爬取了html网页,,怎么能让你运行人家的网页呢你说的加载不出来那是肯定的这个样子应该你只是爬了个外壳,css和js都不能用了,所以背景是白的,按钮都是没有样式的如果明白了,点击右上角给个采纳哦
- 2020-11-29 20:43回答 2 已采纳 直接右键span位置选择copy在选择copy Xpath 获得路径之后后面再加text()
- 2021-04-28 20:55回答 1 已采纳 基本问题,爬数的时候,模拟一下头文件浏览器打开 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWe
- 2022-02-27 16:23小枫Geek的博客 方案一(手动设定响应数据的编码格式): ...方案二(通用处理中文乱码的解决方案): img_name=li.xpath('./a/img/@alt')[0]+'.jpg' #通用处理中文乱码的解决方案 img_name=img_name.encode('iso-8
- 2021-07-24 11:40回答 3 已采纳 你在你画圆圈的的上一行写一句r.encoding="utf-8"试一试,有用的话点一下采纳
- 2018-12-03 07:20回答 3 已采纳 也就是爬取动态图片吧 # coding = utf-8 import urllib.request import re import requests def getDatas(
- 2021-08-10 12:40回答 4 已采纳 没问题的,因为他本身返回的就是从云中君开始的 你打开查看源代码就知道了 你看下他的这个: http://pvp.qq.com/web201605/js/herolist.json
- 2022-11-03 23:28Android__An的博客 【代码】python request爬取网页不显示中文、乱码。
- 2021-09-24 13:08回答 2 已采纳 可以用requests.post获取,需要将参数正确传递。代码可以这么写: import requests import time num=input('input cellphone number:
- 2021-04-03 18:42ppdd·~的博客 使用python爬取小说时文字乱码/爬取图片标题时,中文汉字乱码的解决方法 示例: 爬取链接: https://pic.netbian.com/4kbeijing/.中的背景图片 原始代码: url = 'https://pic.netbian.com/4kbeijing/' page_text = ...
- 2020-11-23 21:41weixin_39976499的博客 [Python] 纯文本查看 复制代码from urllib import parseimport requestsimport webbrowserfrom pyquery import PyQuery as pqdef getPage(keyW):pn = 0#从第1页开始try:while keyW != '':#关键词不能为空url = '...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 cgictest.cgi文件无法访问
- ¥20 删除和修改功能无法调用
- ¥15 kafka topic 所有分副本数修改
- ¥15 小程序中fit格式等运动数据文件怎样实现可视化?(包含心率信息))
- ¥15 如何利用mmdetection3d中的get_flops.py文件计算fcos3d方法的flops?
- ¥40 串口调试助手打开串口后,keil5的代码就停止了
- ¥15 电脑最近经常蓝屏,求大家看看哪的问题
- ¥60 高价有偿求java辅导。工程量较大,价格你定,联系确定辅导后将采纳你的答案。希望能给出完整详细代码,并能解释回答我关于代码的疑问疑问,代码要求如下,联系我会发文档
- ¥50 C++五子棋AI程序编写
- ¥30 求安卓设备利用一个typeC接口,同时实现向pc一边投屏一边上传数据的解决方案。