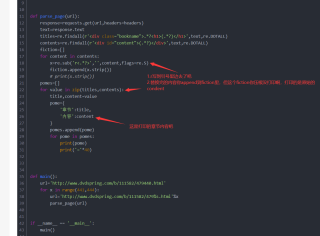
我在这里写了正则替换的代码

但是爬取出来依然会有这些标签并没有替换成空的

我还想把这些也替换掉,麻烦好心人帮我看看是什么问题给我一个思路我该怎么弄才可以
import re
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64',
'Cookie': 'bcolor=; font=; size=; fontcolor=; width=; Hm_lvt_26c0596a5f449ac3144f90f3a3202786=1624770759,1625320560; hitme=1; hitbookid=17577; Hm_lpvt_26c0596a5f449ac3144f90f3a3202786=1625320791',
'Referer': 'http://www.dvdspring.com/b/111582/'
}
def parse_page(url):
response=requests.get(url,headers=headers)
text=response.text
titles=re.findall(r'<div class="bookname">.*?<h1>(.*?)</h1>',text,re.DOTALL)
contents=re.findall(r'<div id="content">(.*?)</div>',text,re.DOTALL)
fiction=[]
for content in contents:
x=re.sub('r<.*?>','',content,flags=re.S)
fiction.append(x.strip())
# print(x.strip())
pomes=[]
for value in zip(titles,contents):
title,content=value
pome={
'章节':title,
'内容':content
}
pomes.append(pome)
for pome in pomes:
print(pome)
print('='*40)
def main():
url='http://www.dvdspring.com/b/111582/479440.html'
for x in range(441,444):
url='http://www.dvdspring.com/b/111582/479%s.html'%x
parse_page(url)
if __name__ == '__main__':
main()
这里是整个代码片段