关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
刘锦城ljc
2021-07-05 22:22
采纳率: 90.9%
浏览 58
首页
Python
已采纳
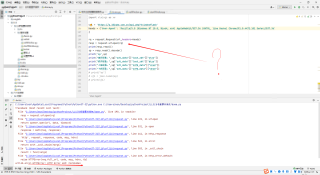
一个Python爬虫问题
python
这是什么意思,怎么改
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
6
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
m0_58995603
2021-07-05 23:03
关注
请求头里加上hexin-v,
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(5条)
向“C知道”追问
报告相同问题?
提交
关注问题
python
爬虫
20个案例
2018-03-25 07:34
讲诉
python
爬虫
的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
81个
Python
爬虫
源代码
2018-12-13 14:23
81个
Python
爬虫
源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的
爬虫
资源
Python
爬虫
详解(一看就懂)
2022-06-21 22:07
练习时长两年半的Programmer的博客
比如我要获取豆瓣电影 Top250 榜单,如果不用
爬虫
,我们要先在浏览器上输入豆瓣电影的 URL ,客户端(浏览器)通过解析查到豆瓣电影网页的服务器的 IP 地址,然后与它建立连接,浏览器再创造
一个
HTTP 请求发送给...
Python
爬虫
系列(一)——手把手教你写
Python
爬虫
2021-10-23 15:47
纸照片的博客
另外,需要强调的是,网络上并不是什么东西都可以爬,针对这个
问题
,我国有着一套完备的法律。爬了不该爬的内容,比如大量个人信息,那可以快速实现“从入门到入狱”。 2. 了解网页 网页一般由三部分组成,分别是 ...
python
爬虫
数据可视化分析大作业.zip
2020-06-12 15:39
在本项目中,"
python
爬虫
数据可视化分析大作业.zip" 是
一个
综合性的学习资源,主要涉及了
Python
编程中的两个重要领域:网络
爬虫
(Web Scraping)和数据可视化(Data Visualization)。通过这个作业,我们可以深入...
【
Python
爬虫
详解】第一篇:
Python
爬虫
入门指南
2025-04-20 09:15
Luck_ff0810的博客
网络
爬虫
(Web Crawler)是一种自动获取网页内容的程序。它可以访问网站,抓取页面内容,并从中提取有价值的数据。在信息爆炸的时代,
爬虫
技术可以帮助我们高效地收集、整理和分析互联网上的海量数据。为了应对不同...
Python
爬虫
完整代码拿走不谢
2023-03-22 09:46
q56731523的博客
对于新手做
Python
爬虫
来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。
Python
万能代码模版:
爬虫
代码篇
2021-09-14 15:27
AI悦创Python一对一辅导的博客
很多同学一听到
Python
或编程语言,可能条件反射就会觉得“很难”。但今天的
Python
课程是个例外,因为今天讲的 **
Python
技能,不需要你懂计算机原理,也不需要你理解复杂的编程模式。**即使是非开发人员,只要...
整理|100个
python
爬虫
项目让你一次吃到撑
2024-07-23 16:17
宇宙大豹发的博客
具体来说,
爬虫
程序会向网站发起HTTP请求,获取网页的HTML代码、JSON数据或二进制数据(如图片、视频等),然后利用解析库对获取的数据进行解析,提取出所需的信息,最后将这些信息存储到本地文件、数据库或其他存储...
28个精品
Python
爬虫
实战项目
2023-03-04 17:19
秃头雨雨的博客
Python
当然是这类的赢家,它的语法容易,简单易学,
Python
允许...
Python
是所有编程语言里面,代码量最低,非常易于读写,遇到
问题
时,程序员可以把更多的注意力放在
问题
本身上,而不用花费太多精力在程序语言、语法上。
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
 关注
关注 
 微信扫一扫
微信扫一扫 分享
分享