
今天在搭建ElasticSearch时候 出现的问题 显示Nodes的问题:
019-01-18 23:20:34.462 ERROR 12264 --- [ main] .d.e.r.s.AbstractElasticsearchRepository : failed to load elasticsearch nodes : org.elasticsearch.client.transport.NoNodeAvailableException: None of the configured nodes are available: [{#transport#-1}{mfQlD8ZeTIOtTnLapBR5pA}{192.168.1.105}{192.168.1.105:9300}]
springboot版本:
2.1.2.RELEASE
springboot data elasticsearch 版本: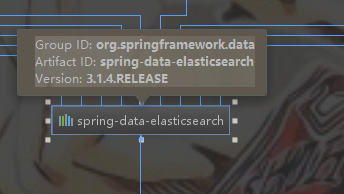
properties配置文件内容如下:
spring.elasticsearch.jest.uris=http://192.168.1.105:9200/
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=192.168.1.105:9300
elasticsearch 浏览器中显示如下:
{
"name" : "Rigellian Recorder",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "MU7QHYyfR6CoTImE1BpjEQ",
"version" : {
"number" : "2.4.6", "build_hash" : "5376dca9f70f3abef96a77f4bb22720ace8240fd",
"build_timestamp" : "2017-07-18T12:17:44Z",
"build_snapshot" : false,
"lucene_version" : "5.5.4" },
"tagline" : "You Know, for Search" }





