
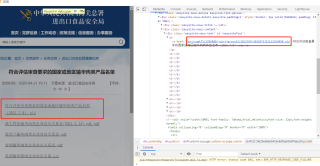
很简单的一个url:http://jckspj.customs.gov.cn/spj/zwgk75/2706880/jckrljgzyxx33/2812399/index.html,为何我没有获取到,这不是js动态生成的页面啊,我只想获取这几个链接的url,但是request返回一堆js是怎么回事 。
 ,
,
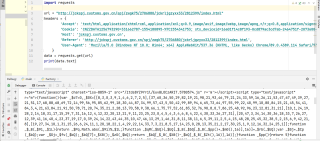

很简单的一个url:http://jckspj.customs.gov.cn/spj/zwgk75/2706880/jckrljgzyxx33/2812399/index.html,为何我没有获取到,这不是js动态生成的页面啊,我只想获取这几个链接的url,但是request返回一堆js是怎么回事 。
,
 分享
分享
网站设置有debugger反爬,不允许页面调试,需要寻找相应的解决办法哦,望采纳
分享 已采纳回答
7月15日
创建了问题
7月15日
已采纳回答
7月15日
创建了问题
7月15日



