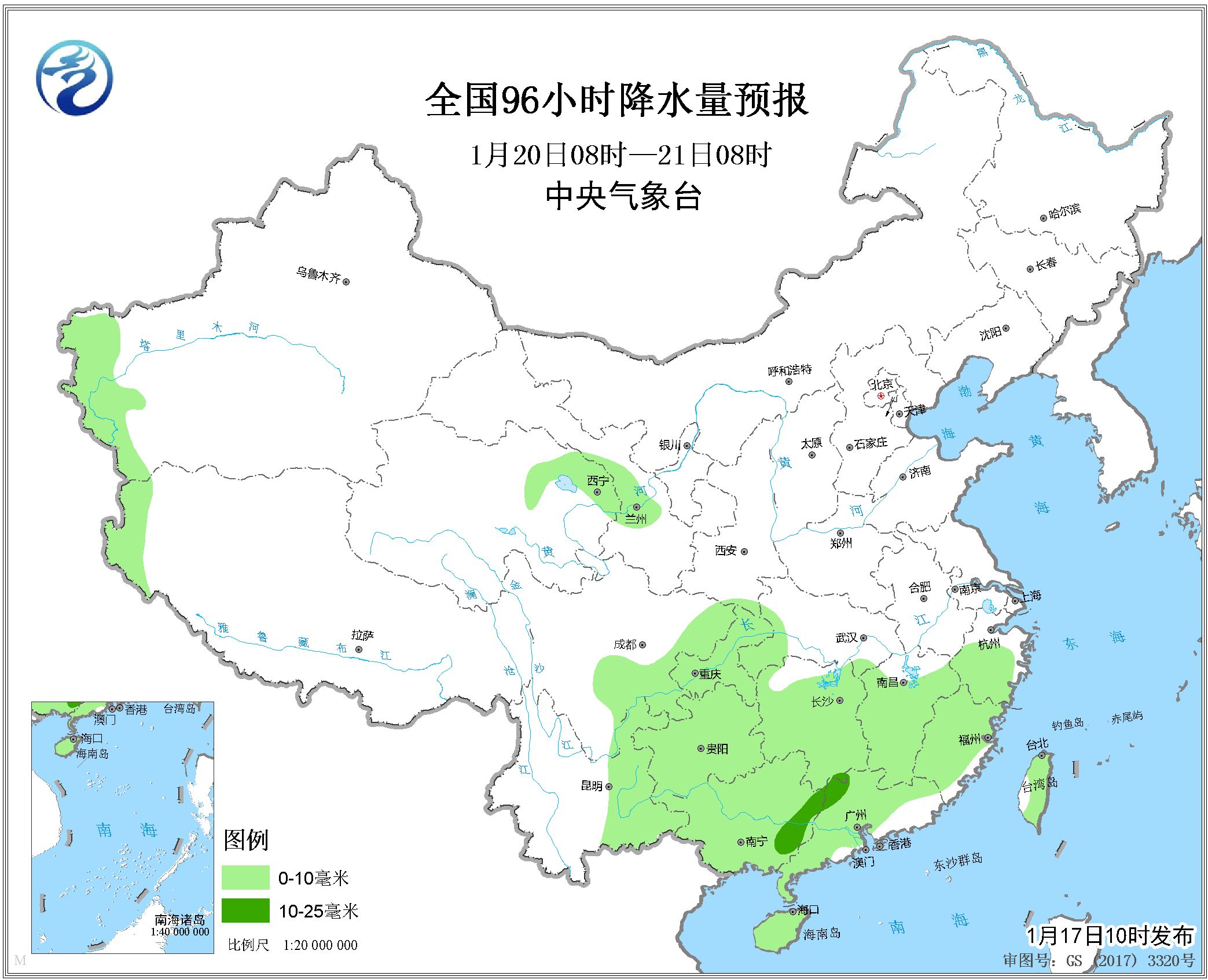
要从中国气象台网降水量预警图片提取降水量信息,转换成文字形式,有什么提取思路,给个建议啊,谢谢大家了!!用python开发。。

python 图像识别处理 中国气象台网降水量图片信息提取

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 lyhsdy 2019-01-22 17:34关注
lyhsdy 2019-01-22 17:34关注←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
http://www.nmc.cn/publish/observations/24hour-precipitation-05.html
这图片下面有对应的数字啊,为什么要用图片转文字
然后再用python爬虫就可以了解决评论 打赏无用 1举报 分享
- 2022-06-29 14:08回答 4 已采纳 比想象中的复杂啊,先凑合出来第一题了,结果是这样的:
- 2021-09-15 19:44回答 3 已采纳 400400的图片处理什么东西需要1600016000的矩阵来处理?你的问题解决方法也简单,既然是稀疏矩阵,那么就用稀疏矩阵的方式来存储和计算就行了
- 2023-03-08 13:33回答 1 已采纳 不知道你这个问题是否已经解决, 如果还没有解决的话: 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:Python实战案例:PyQT模块开发多线程视频播放器(下)如果你已经解决了该问题
- 2020-12-10 04:12weixin_39611769的博客 一、Python环境搭建下载安装python下载安装PyCharm,Community版即可理论上应该先安装python再安装IDE(PyCharm),必要时按网上要求进行环境变量设置。二、爬虫背景知识1.网页结构简介网页一般由三部分组成:HTML(超...
- 2023-01-08 10:36回答 1 已采纳 在进行数据处理之前,你可以使用一个掩膜来筛选出你感兴趣的区域。这样可以减少计算量,也可以避免将不需要的数据带入计算。 掩膜可以是一个二维布尔数组,表示哪些网格是需要保留的。例如,如果你想计算纬度在 2
- 2022-04-21 16:48回答 5 已采纳 torch.zeros()是创建0向量。参考一下这个吧。大概思路就是先给图片路径,然后加载图片,再可选地对图片进行处理,最后放进去模型就可以输出了。 normalize = transforms.No
- 2022-07-17 21:00回答 2 已采纳 搜侵蚀和膨胀,这是opencv的基本功,网上资料数不胜数。
- 2020-12-10 04:13weixin_39548438的博客 全国天气降水量预报图接口 免费在线测试此接口(需要登录)接口每两小时更新一次,一天调取1-2次即可,返回3张图:24、48、72小时,请勿频繁调用!。请求方式及url:请求方式:GET接口地址:https://tianqiapi.com/api...
- 2023-01-17 12:39回答 2 已采纳 Tesseract-OCR:一个开源的OCR引擎,可以识别多种语言的文字。pytesseract:一个Python封装的Tesseract-OCR库,可以在Python中调用Tesseract-OCR
- 2022-05-03 17:03回答 3 已采纳 打上标签,进行模型训练,得出来json文件,检擦label一栏的数据,一般如果是以框来的话则中心坐标是两个坐标求均值。
- 2021-06-14 23:01回答 2 已采纳 参考一下:https://blog.csdn.net/qq_41895190/article/details/82791426 如果对你有帮助,可以点击我这个回答右上方的【采纳】按钮,给我个采纳吗,
- 2021-01-29 17:18weixin_39884100的博客 # 引用部分import numpy as npimport pandas as pdfrom scipy.interpolate import Rbf# 径向基函数 : 将站点信息插到格点上 用于绘制等值线import matplotlib.pyplot as pltimport matplotlib.colors as ...
- 2022-04-10 16:15回答 1 已采纳 挺复杂的这个是个入门文章https://www.jb51.net/article/215653.htm
- 2020-12-03 21:09weixin_39845825的博客 python能快速解决日常工作中的小任务,比如数据展示。python做数据展示,主要用到matplotlib库,使用简单的代码,就可以很方便的绘制折线图、柱状图等。使用Java等,可能还需要配合html来进行展示,十分繁琐。各种...
- 2020-12-03 21:09weixin_39955732的博客 一、Python环境搭建下载安装python下载安装PyCharm,Community版即可理论上应该先安装python再安装IDE(PyCharm),必要时按网上要求进行环境变量设置。二、爬虫背景知识1.网页结构简介网页一般由三部分组成:HTML(超...
- 没有解决我的问题, 去提问


悬赏问题
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码
- ¥15 js调用html页面需要隐藏某个按钮