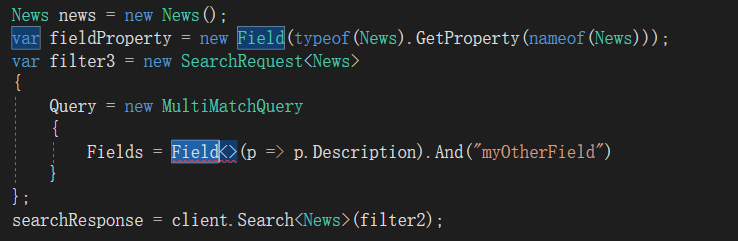
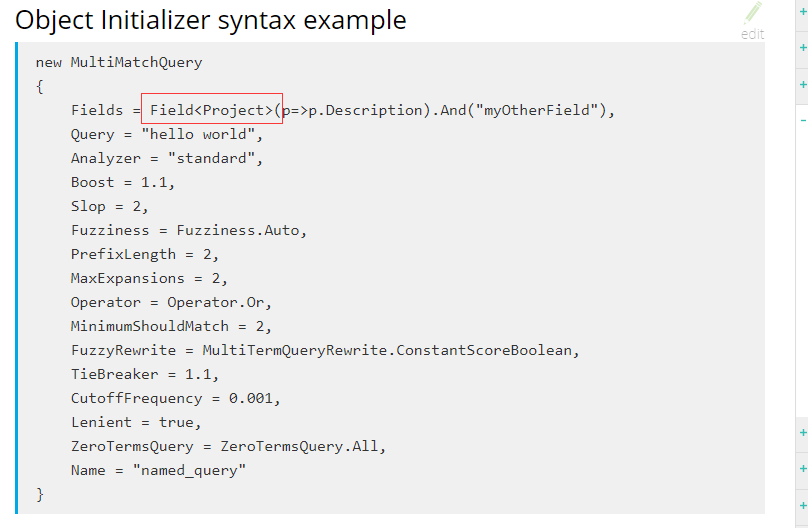
请问Fields = Field(p=>p.Description).And("myOtherField"),Project怎么填

C#操作ElasticSearch Field泛型问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
- 会咏春拳的钢铁侠的爸 2019-01-23 09:38关注
Field使用Nest.Infer命名空间的就是正常的了
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2024-03-27 17:18鲨鱼辣椒ii的博客 除了上边这些场景外,加入现在要写一个帮助类,遇到一个问题,根据传入对象的不同,返回不同的类型。反射是.net提供的一个强大的功能机制,可以在运行时,动态的更改操作对象的类型。通过使用反射,程序可以动态的...
- 2021-11-13 20:41后端阿一的博客 一、ElasticSearch 简介 1.什么是 ElasticSearch? Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别...
- 2022-03-16 16:11蓝桉不遇释怀的博客 ElasticSearch简介 ElasticSearch:智能搜索,分布式搜索引擎。 是ELK的一个组成。是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K即使Kibana E:ElasticSearch 搜索和分析的...
- 2020-11-30 01:32weixin_39716510的博客 Elasticsearch是一款优秀的开源搜索引擎,其除了可以完成复杂的query请求外,还可以做一些统计聚合的任务,类似sql中的max、sum、count、avg等。事情的缘起在于某一次对Elasticsearch的性能测试中发现,countAgg的...
- 2021-04-28 15:51君を見つけて的博客 (三)ElasticSearch 批量操作与高级查询 准备数据 一.创建招聘信息结构化索引 # put:127.0.0.1:9200/recruitment { "settings":{ "index":{ "number_of_shards":"5", "number_of_replicas":"0" } }, "mappings":{ ...
- 2024-09-18 10:04鸡c的博客 es基本请求格式提示:以下是本篇文章正文内容,下面案例可供参考封装四个操作:索引创建,数据新增,数据查询,数据删除封装最主要要完成的是请求正文的构造过程: Json::Value 对象的数据新增过程索引创建:1....
- 2022-09-14 22:45小帅学编程的博客 配置文件地址:elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml,由于配置的分词器是对应的网络地址,因此,我们需要搭一个Nginx。
- 2022-01-25 14:45sslyc8991的博客 本文将以C#版本为时间线,从C#1.0到C#10.0系统梳理每个版本的语法,并同时就语法机制与Java做出详细的对比。方便读者同时了解两门语言的特点。
- 2020-06-09 22:30「已注销」的博客 1. Elasticsearch简介 Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,...
- 2024-09-26 10:33Leon_Jinhai_Sun的博客 Elasticsearch 搜索操作示例
- 没有解决我的问题, 去提问
