import uiautomator2 as u2
import threading
import os
# coding=utf-8
# noinspection PyUnresolvedReferences
from urllib.request import quote, unquote
# noinspection PyUnresolvedReferences
from lxml import etree
from selenium import webdriver
import time
# noinspection PyUnresolvedReferences
import requests
from selenium.webdriver.firefox.options import Options
import requests
from bs4 import BeautifulSoup
d = u2.connect("127.0.0.1:62001")
# p=d(resourceId="com.baidu.iknow:id/qb_question_title_tv").get_text()
d
def b():
while True:
time.sleep(2)
if d(text="发 布"):
time.sleep(1)
p = d.xpath('//*[@resource-id="app"]/android.view.View[3]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]').get_text()
print(p)
driver = webdriver.Chrome(executable_path="D:\桌面\编程\python\环境变量\chromedriver.exe")
driver.get('https://baidu.com')
driver.find_element_by_id("kw").send_keys("site:zhidao.baidu.com " + p)
driver.find_element_by_id("su").click()
driver.find_element_by_id("su").click()
time.sleep(1)
elem1 = driver.find_element_by_link_text("百度知道")
elem1.click()
time.sleep(2)
#切换当前标签
driver.switch_to.window(driver.window_handles[1])
#用这个获取url
print(driver.current_url)
time.sleep(1)
url = driver.current_url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
r.encoding = "gbk"
print(r.status_code)
soup = BeautifulSoup(r.text, 'html.parser')
hh=div = soup.body.find('div',class_='best-text mb-10')
if hh == None:
div = soup.body.find('div', class_='answer-text mb-10 line')
div_list = div.contents[1:]
print('开始提取文字1')
for i in div_list:
if str(i) != '<p>':
print(i)
else:
div_list=div.contents[2:]
print('开始提取文字1')
for i in div_list:
if str(i)!='<br/>':
print(i)
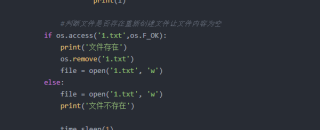
#判断文件是否存在重新创建文件让文件内容为空
if os.access('1.txt',os.F_OK):
print('文件存在')
os.remove('1.txt')
file = open('1.txt', 'w')
else:
file = open('1.txt', 'w')
print('文件不存在')
time.sleep(1)
#读取1.txt内容
with open('1.txt', 'a+', encoding='utf-8') as f:
#文本内容加获取的内容写入文本
bb = f.write(i)
print("文本写入状态:"+str(bb)+'\n')
f.close()
driver.quit()
#读取需要输入的内容
n = open('1.txt',encoding="utf-8")
o = n.read()
u =d.xpath('//android.widget.EditText').click()
#输入获取的文本内容
d.send_keys(o)
o.close()
print("文字输入状态:"+str(u))
time.sleep(0.3)
d.xpath('//*[@text="发 布"]').click()
time.sleep(3)
def v():
while True:
if d.xpath('//*[@resource-id="app"]/android.view.View[3]/android.view.View[1]/android.view.View[1]/android.view.View[2]'):
pass
else:
time.sleep(2)
d(text='回答').click()
t2 = threading.Thread(target=b,args=())
t2.start()
t3 = threading.Thread(target=v,args=())
t3.start()
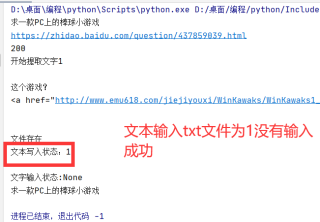
获取百度知道问题答案回答问题,问题是一行一行的输入只能输入一行,把获取的每一行内容写入文本获取文本内容,输入,只能把最后一行写入文本,错误不知道怎么解决