关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
weixin_44954356
2021-07-22 10:03
采纳率: 80%
浏览 58
首页
有问必答
已结题
python爬虫scrapy
有问必答
python
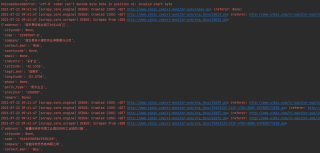
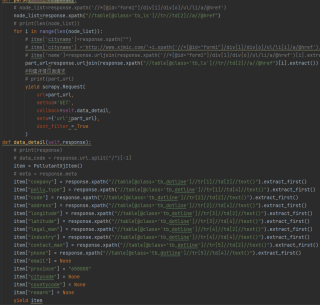
运行爬虫数据不能全部正常提取只能提取部分数据,爬虫以及执行结果都在下面截图,,抱拳
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
栀子花海
2021-08-02 17:34
关注
看下数据是否是动态加载的,多抓几次包,分析下;可能需要通过添加page参数,进行爬取!
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
爬虫
框架
Scrapy
教程《PDF文档》
2024-10-02 21:27
《
Python
爬虫
框架
Scrapy
教程》主要是针对学习
python
爬虫
的课程,又基础的
python
爬虫
框架
scrapy
开始,一步步学习到最后完整的
爬虫
完成,现在
python
爬虫
应用的非常广泛,本文档详细介绍了
scrapy
爬虫
和其他
爬虫
技术的...
Python
爬虫
框架
Scrapy
教程 完整版PDF
2023-04-06 14:20
《
Python
爬虫
框架
Scrapy
教程》主要是针对学习
python
爬虫
的课程,又基础的
python
爬虫
框架
scrapy
开始,一步步学习到最后完整的
爬虫
完成,现在
python
爬虫
应用的非常广泛,本文档详细介绍了
scrapy
爬虫
和其他
爬虫
技术的...
py
爬虫
Python
爬虫
Scrapy
培训源码
2023-11-23 17:07
py
爬虫
Python
爬虫
Scrapy
培训源码,py
爬虫
Python
爬虫
Scrapy
培训源码,喜欢的同学可以下载研究
Python
爬虫
Scrapy
框架
2023-06-01 09:18
基础的框架,适合入门选手
爬虫
代码实例源码大全+
Python
爬虫
Scrapy
课件源码.zip
2024-03-27 03:27
通过学习和实践其中的代码,用户不仅可以掌握
Python
爬虫
的基础知识,还能深入了解
Scrapy
框架的高级功能,提升网络数据抓取和处理的能力。对于想要从事数据采集、数据分析或者Web开发的人来说,这是一个非常有价值的...
精通
Python
爬虫
框架
Scrapy
.pdf
2020-12-20 13:57
精通
Python
爬虫
框架
Scrapy
.pdf
基于
Python
爬虫
Scrapy
课件源码.zip
2024-05-11 20:54
python
课程设计基于
Python
爬虫
Scrapy
课件源码基于
Python
爬虫
Scrapy
课件源码基于
Python
爬虫
Scrapy
课件源码基于
Python
爬虫
Scrapy
课件源码基于
Python
爬虫
Scrapy
课件源码基于
Python
爬虫
Scrapy
课件源码基于
Python
...
Python
爬虫
Scrapy
框架测试案例
2022-03-20 10:30
Python
爬虫
Scrapy
框架测试案例
python
爬虫
scrapy
框架基础
2022-12-05 21:37
进击的章鱼哥的博客
我是按照《精通
python
网络
爬虫
核心技术框架与项目实战》这本书来写的。讲的比较简洁,想要详细了解的可以看看书或者视频。
scrapy
框架运行的原理首先
scrapy
引擎会将蜘蛛
爬虫
(spider)中设置的起始网址传递到调度器中第...
基于
Python
的
Scrapy
爬虫
项目设计源码
2024-09-23 16:44
本项目即是利用
Scrapy
框架进行设计的
爬虫
源码,具体表现为一个包含大量文件的压缩包,其中绝大多数为图片资源,另有文档和核心的
Python
爬虫
代码,适合于不同的数据抓取需求。
Scrapy
是
Python
开发的一个快速、高层次...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
9月3日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
8月26日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
7月22日

 分享
分享 分享
分享 系统已结题
9月3日
系统已结题
9月3日 已采纳回答
8月26日
创建了问题
7月22日
已采纳回答
8月26日
创建了问题
7月22日


