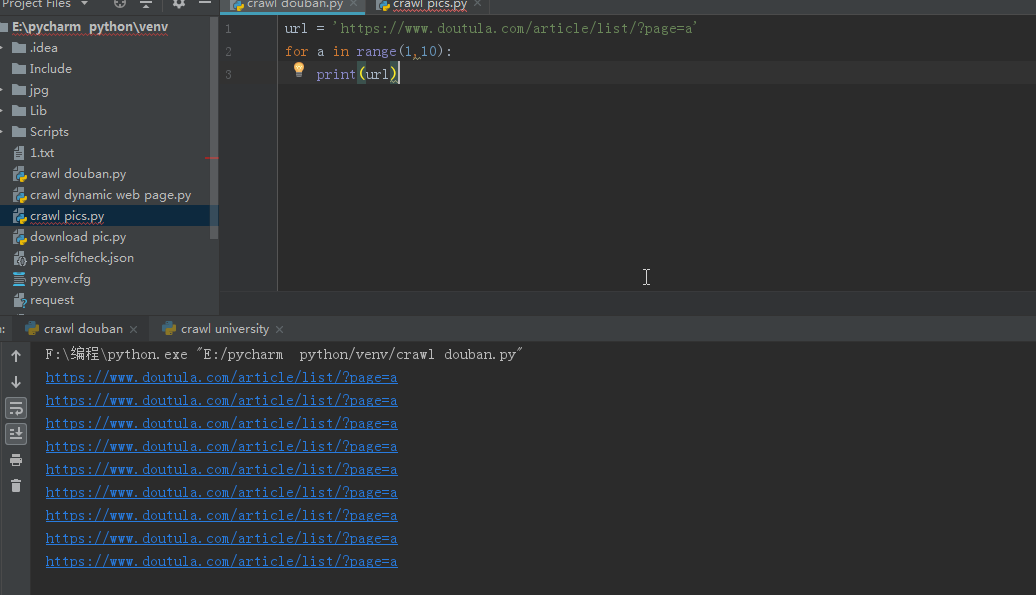
我想爬取一个分页数据,为什么这段代码的结果是这个?
收起
←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
for a in range(1,10): url=r'https://xxxxxx?page='+str(a) print(url)
报告相同问题?


 分享
分享 分享
分享

