

代码里面写了utf-8
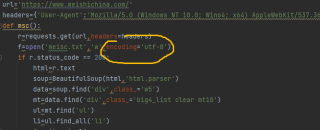
text文件中文还是乱码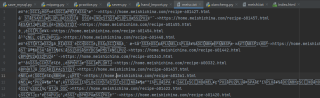
附上代码:
import requests
from bs4 import BeautifulSoup
url='https://www.meishichina.com/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71'}
def msc():
r=requests.get(url,headers=headers)
f=open('meisc.txt','w',encoding='utf-8')
if r.status_code == 200:
html=r.text
soup=BeautifulSoup(html,'html.parser')
data=soup.find('div',class_='w5')
mt=data.find('div',class_='big4_list clear mt10')
ul=mt.find('ul')
li=ul.find_all('li')
for item in li:
a=item.find(target='_blank')
title=a.attrs['title']
href = a.attrs['href']
f.write(f'{title}->{href}\n')
f.close()
if __name__ == '__main__':
msc()








