
我是刚学python 我是垃圾 大 1神救1救我
代码中的网址输入百度的网址,运行结果显示窗口出现一大串数据,但是为什么换了哔哩哔哩的网址就不行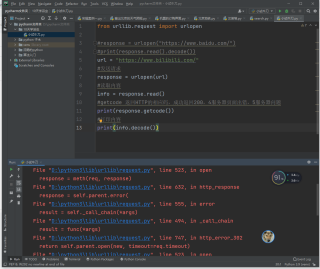

为什么我python爬虫代码爬百度可以 爬bilibili不行

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 CSDN专家-showbo 2021-07-24 14:40关注
CSDN专家-showbo 2021-07-24 14:40关注bilibili加了反扒,你代码没加请求头user-agent,禁止访问了。有帮助麻烦点个采纳【本回答右上角】,谢谢~~

改成下面的就行
from urllib.request import urlopen import urllib url="https://www.bilibili.com/" req = urllib.request.Request(url, None, {"user-agent":" Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Mobile Safari/537.36"}) response=urlopen(req) info=response.read() print(response.getcode()) print(info.decode())本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2024-03-29 10:07B站视频python爬虫下载,注意修改video_bvid,通过视频链接可以查看。B站视频python爬虫下载,注意修改video_bvid,通过视频链接可以查看。B站视频python爬虫下载,注意修改video_bvid,通过视频链接可以查看。B站...
- 2023-11-27 20:02代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~bilibili视频下载Bilibili视频下载是指通过爬虫脚本从Bilibili网站上下载视频,以便在本地进行观看或其他用途。2. 实现目标...
- 2023-11-20 22:08这是一个用于在Bilibili平台上进行用户信息抓取的Python爬虫程序。通过该程序,用户可以自动获取Bilibili上的用户信息,包括用户ID、昵称、关注数、粉丝数、投稿视频等数据,实现批量采集和分析Bilibili用户信息的...
- 2024-05-11 20:58Python爬虫示例之bilibili-user-masterPython爬虫示例之bilibili-user-masterPython爬虫示例之bilibili-user-masterPython爬虫示例之bilibili-user-masterPython爬虫示例之bilibili-user-masterPython爬虫示例之...
- 2023-11-27 20:02代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~代码仅供参考学习~bilibili自动登录Bilibili自动登录是指通过爬虫脚本模拟用户在Bilibili网站上进行自动登录,以方便执行需要登录权限的操作...
- 2023-12-22 10:45Python爬虫程序是数据获取的重要工具,尤其在信息丰富的互联网时代,它可以帮助我们自动化地从网站上抓取大量数据。本压缩包包含了针对163网易、百度、百度云、哔哩哔哩以及中国知网这五个不同平台的爬虫程序源代码...
- 2024-11-12 11:30Bilibili用户爬虫 **该爬虫仅供学习使用** ## 文件介绍 * `bilibili_user.py`:爬虫文件 * `bilibili_user_info.sql`:数据库文件 * `get_face.py`:用户头像下载器 ## Bilibili用户报告(Web App) 演示地址:...
- 2023-09-12 16:39【Python爬虫基础】 Python是一种广泛应用于Web开发、数据分析、机器学习等领域的编程语言,尤其在爬虫领域表现突出。Python的爬虫框架如BeautifulSoup、Scrapy等,提供了便捷的方式来抓取和处理网页数据。 ...
- 2023-11-21 13:13python爬虫案例大全,一些爬虫示例程序,以及模拟登陆程序,模拟登陆基于 selenium,有些模拟登录基于 js 逆向。模拟登陆基本采用的是直接登录或者使用selenium+webdriver的方式,有的网站直接登录难度很大,比如qq...
- 2023-09-10 09:38本教程将聚焦于如何使用Python爬虫来实现某站(假设为B站,即哔哩哔哩)电脑端视频的下载保存。 首先,我们需要了解B站视频的网页结构和数据获取方式。B站视频页面中的视频源通常是以m3u8格式的分段TS文件存在,...
- 2023-07-27 10:13### Python爬虫案例知识点 #### 一、Python爬虫简介 Python爬虫是一种利用Python语言编写的自动化程序,主要用于从互联网上抓取所需的信息。它能够高效地收集大量的数据,并将其整理成便于分析和使用的格式。 ###...
- 2022-06-06 21:463、Python爬虫自学资料 B站视频课程地址:https://www.bilibili.com/video/BV1oU4y1y7Se/ 整个课程学完,即可掌握爬虫原理与操作,遇到问题欢迎私聊我,我们一起探讨! 项目资料收集不易,感谢您的理解与支持!
- 2024-10-07 13:03* BaiJiaHao--百家号爬虫 获取百度热搜事件的搜索结果中百家号所占的比例. * Bilibili--B站直播弹幕爬虫 多线程爬虫爬取B站比赛直播弹幕,弹幕数量七万多条,并根据弹幕内容生成词云。 * Blogs--博客园爬虫 爬取...
- 2024-06-12 09:37【Python爬虫项目:Bilibili-User-Master】 该项目是一个使用Python编写的B站(哔哩哔哩)用户信息爬虫。Bilibili是中国知名的弹幕视频分享网站,拥有大量的用户和活跃社区。通过爬取B站用户数据,我们可以进行用户...
- 2025-01-12 21:09白雪公主的后妈的博客 主要内容:模拟bilibili账号密码登录,不要实现的的实现功能是单击登录按钮,切换登录方式, 输入账号和密码,然后完成图片点击验证,最后单击立即登录按钮。...2、第二步:识别图片中图形的位置。...
- 2020-11-22 11:46weixin_39869043的博客 原博文2020-06-04 16:19 −最近在学习python,不过有一个正则表达式一直搞不懂,自己直接使用最笨的方法写出了一个百度爬虫,只有短短16行代码。首先安装必背包:pip3 install bs4pip3 install requests安装好后,...
- 2024-10-08 09:43Python作为一种简洁易学的编程语言,在开发网络爬虫方面表现出色,尤其是Python3版本,它为网络爬虫开发者提供了强大的库支持和开发环境。 本项目《基于Python3的Web爬虫设计与实现源码》是一套完整的网络爬虫开发...
- 2023-01-31 19:11爬虫python入门 :dolphin:基于python实现的各种小爬虫 :dolphin:每一个文件夹就是一个小爬虫,具体可见每个文件夹下的readme文件 :dolphin:持续更新中,欢迎star/fork :dolphin:基于python实现的各种小爬虫 :...
- 2024-08-14 22:50Python网络爬虫配套学习资料 视频链接:https://www.bilibili.com/video/BV1rieneBEJF/?spm_id_from=333.999.0.0&vd_source=9e95d419d6200580770202fc64e66cf8
- 2024-05-10 02:04阿勉要睡觉的博客 网络爬虫,也称为网页蜘蛛或网络机器人,是一种自动抓取万维网信息的程序或脚本。爬虫的基本原理是通过模拟人的网络行为,如点击按钮、查看数据等,来获取服务器上的数据。这些数据可以是文本、图片、视频等多种格式...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
8月1日
系统已结题
8月1日 已采纳回答
7月24日
已采纳回答
7月24日-
创建了问题
7月24日