
我写了一个多进程和多线程结合的爬虫(我不知道多进程和多线程怎样结合使用)所以我先说一下**我的思路**:
- 首先我爬取的是某车之家的文章
- 汽车之家有很多种车,比如奥迪,宝马,奔驰,我创建一个进程池pool, 对应每一种车创建一个进程下载它的文章
- 然后,因为每种车下面有很多篇文章,我创建一个线程池,对应每一篇文章,创建一个线程来下载文章
- 创建进程池我使用的是multiprocessing.Pool
- 创建线程池使用的是concurrent.futures.ThreadPoolExecutor
那么现在问题来了
- 当我刚开始运行我的代码的时候,因为我创建的进程池大小是cpu_count()=8,所以打开任务管理器可以看到8个python进程正在运行
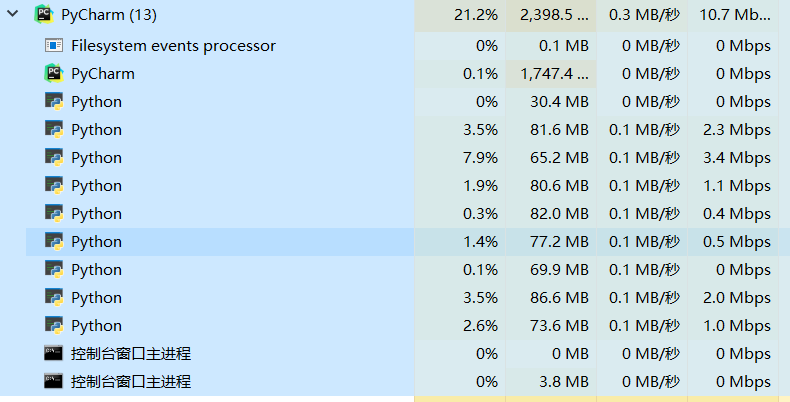
-
然后,当代码运行一段时间后,进程池中的8个进程全部停止运行了


可以看到此时代码并没有运行完毕,而且代码运行卡在这里无论等多久都不会继续运行
- 我观察发现,这些进程在下载某辆车如本田-雅阁的所有文章后,注意是将所有文章下载完毕才会停止运行,而且不再运行
我想知道进程池中的进程为什么会停止运行,而我的函数没有停止?可以确定的是我的爬虫任务并没有全部完成,仅仅完成了一小部分。进程池中的每一个进程在爬取几辆车的所有文章后停止运行,求大佬解答,不甚感激。
代码如下
# coding=utf-8
import requests
import os
import re
import json
import time
import random
import threading
import multiprocessing
import concurrent.futures
from bs4 import BeautifulSoup
def change_title(title):
rstr = r"[\/\\\:\*\?\"\<\>\|]"
return re.sub(rstr, "", title)
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
http_ip = list()
https_ip = list()
with open(r'D:\pycharm\Spider\99mm\useful_ip.txt', 'r') as fp:
lines = fp.readlines()
for line in lines:
ips = eval(line)
if str(ips['kind']) == 'HTTP':
http_ip.append(ips['proxy'])
else:
https_ip.append(ips['proxy'])
def get_all_cars(main_url, file_path):
car_dict = {}
html = requests.get(main_url)
soup = BeautifulSoup(html.text, "html.parser")
catalog = soup.find("div", id="hotcar-1").find_all("div", class_="name")
for cata in catalog[-1:]:
# suv, 紧凑型车, 中型车
cata_a = cata.find("a")
print(cata_a["href"])
print(cata_a.get_text())
car_url = main_url + cata_a["href"]
car_html = requests.get(car_url)
car_soup = BeautifulSoup(car_html.text, "html.parser")
# 有4个 class_="tab-content-item"
car_letter_boxes = car_soup.find("div", class_="tab-content-item").find_all("div", class_="uibox")
for car_letter_box in car_letter_boxes[:]:
# 车牌按字母排序 A~Z, 一个字母下有很多车牌, 对每个字母进行处理
car_brand_info = car_letter_box.find("div", class_="uibox-con rank-list rank-list-pic")
if car_brand_info:
car_brands = car_brand_info.find_all("dl", olr=re.compile("^.*$"))
for car_brand in car_brands:
# 一个车牌有很多种车型, 对每个车牌进行处理
brand_name = car_brand.find("div").find("a").get_text()
print("-car brand-", brand_name)
car_dict[cata_a.get_text() + "-" + brand_name] = {}
car_brand_path = main_path + "\\" + cata_a.get_text() + "-" + brand_name
if not os.path.exists(car_brand_path):
os.mkdir(car_brand_path)
# os.chdir(car_brand_path)
car_name_lists = car_brand.find_all("ul", class_="rank-list-ul")
for car_name_list in car_name_lists:
car_name_lis = car_name_list.find_all("li", id=re.compile("^.*$"))
for car_name_li in car_name_lis:
car_a_tag = car_name_li.find("h4").find("a")
specific_car_url = "https:" + car_a_tag["href"]
car_name = car_a_tag.get_text()
print("\t", car_name, "\t", specific_car_url)
car_dict[cata_a.get_text() + "-" + brand_name][car_name] = specific_car_url
brand_cars_path = car_brand_path + "\\" + car_name
if not os.path.exists(brand_cars_path):
os.mkdir(brand_cars_path)
# os.chdir(brand_cars_path)
# 至此, 找到了每一辆车的url, 需要从这个url中找到它对应的一系列文章
# get_each_car_articles(main_url, specific_car_url)
else:
continue
return car_dict
def get_each_car_articles(main_url, specific_car_url, file_path, headers, proxies, info):
# main_url, specific_car_url, file_path, headers, proxies, info = args
# 传入的是每一种车的url, 即specific_car_url
article_dict = {}
specific_car_html = requests.get(url=specific_car_url, headers=headers, proxies=proxies)
specific_car_soup = BeautifulSoup(specific_car_html.text, "html.parser")
art_temp = specific_car_soup.find("div", class_="athm-sub-nav__channel athm-js-sticky")
if art_temp:
art = art_temp.find_all("li")
else:
print(f"\t\t****article is None, url is {specific_car_url}****")
return
part_url = art[6].find("a")["href"]
specific_car_article_url = main_url + part_url
right_pos = specific_car_article_url.rfind("/")
specific_car_article_url = specific_car_article_url[:right_pos + 1]
specific_car_article_html = requests.get(specific_car_article_url, headers=headers, proxies=proxies)
specific_car_article_soup = BeautifulSoup(specific_car_article_html.text, "html.parser")
page_info = specific_car_article_soup.find("div", class_="page")
page_num = 1
if page_info:
pages = page_info.find_all("a", target="_self")
page_num = int(pages[-2].get_text())
for i in range(1, page_num + 1):
if i == 1:
page_url = specific_car_article_url
else:
page_url = specific_car_article_url[:-4] + str(i) + specific_car_article_url[-3:]
# print("\t"*2, f"正在查找第{i}页的文章\t", page_url)
page_html = requests.get(page_url, headers=headers, proxies=proxies)
page_soup = BeautifulSoup(page_html.text, "html.parser")
articles = page_soup.find("div", class_="cont-info").find_all("li")
for article in articles:
each_article = article.find("h3").find("a")
each_article_url = "https:" + each_article["href"]
each_article_title = each_article.get_text()
article_dict[each_article_title] = each_article_url
os.chdir(file_path)
with concurrent.futures.ThreadPoolExecutor(max_workers=8) as t_executor:
for key, value in article_dict.items():
t_executor.submit(download_each_article, *(value, key,info))
# thread_list = []
# for key, value in article_dict.items():
# thread_list.append(threading.Thread(target=download_each_article, args=(value, key,info)))
# [thread.start() for thread in thread_list]
# [thread.join() for thread in thread_list]
def download_each_article(each_article_url, each_article_title, info):
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Referer": "https://www.autohome.com.cn"
}
proxies = {"proxy": random.choice(http_ip)}
# each_article_url, each_article_title, headers, proxies, info = args
print(f"\t\t--下载文章-- {info}\t{each_article_title}\t{each_article_url}")
article_html = requests.get(each_article_url, headers=headers, proxies=proxies)
article_soup = BeautifulSoup(article_html.text, "html.parser")
article_content = article_soup.find("div", class_="container article")
if article_content:
with open(f"{change_title(each_article_title)}.txt", "w+", encoding="utf-8") as f:
time_span = article_content.find("div", class_="article-info").find("span", class_="time")
time = time_span.get_text()
time_dict = {"time": time}
f.write(json.dumps(time_dict) + "\n\n")
article_content_div = article_content.find("div", id="articleContent")
for content in article_content_div.find_all("p"):
if content.get_text().strip():
content_dict = {"content": content.get_text()}
f.write(json.dumps(content_dict) + "\n")
else:
try:
imgs = content.find_all("a")
for i in imgs:
img = i.find("img")
img_dict = {f"<[image] {img['alt']}> ": "https:" + img["src"]}
f.write(json.dumps(img_dict) + "\n")
except:
continue
pages = article_content.find("div", class_="athm-page__num")
if pages:
for a in pages.find_all("a", target="_self")[1:]:
next_page_url = "https://www.autohome.com.cn" + a["href"]
pages_html = requests.get(next_page_url, headers=headers, proxies=proxies)
pages_soup = BeautifulSoup(pages_html.text, "html.parser")
pages_content_div = pages_soup.find("div", class_="container article").find("div", id="articleContent")
for content in pages_content_div.find_all("p"):
if content.get_text().strip():
content_dict = {"content": content.get_text()}
f.write(json.dumps(content_dict) + "\n")
else:
try:
imgs = content.find_all("a")
for i in imgs:
img = i.find("img")
img_dict = {f"<[image] {img['alt']}> ": "https:" + img["src"]}
f.write(json.dumps(img_dict) + "\n")
except:
continue
# 下载评论
f.write("\n")
article_comment_span = article_content.find("div", "article-tools").find("span", class_="comment")
article_comment_url = "https:" + article_comment_span.find("a")["href"]
# print(article_comment_url)
basic_reply_url = "https://reply.autohome.com.cn/api/comments/show.json?count=50&" \
"page={}&id={}&appid=1&datatype=jsonp&order=0&replyid=0"
html = requests.get(article_comment_url, headers=headers, proxies=proxies)
html_soup = BeautifulSoup(html.text, "html.parser")
article_id = re.search(r"articleid=([\d]*)#", article_comment_url).groups()[0]
first_json_dict = json.loads(requests.get(basic_reply_url.format(1, article_id), headers=headers, proxies=proxies).text[1:-1])
page_num = int(first_json_dict["commentcount"]) // 50 + 1
for i in range(1, page_num + 1):
json_dict = json.loads(requests.get(basic_reply_url.format(i, article_id)).text[1:-1])
comment_dicts = json_dict["commentlist"]
for comment in comment_dicts:
comment_dict = {}
comment_dict["RMemberId"] = comment["RMemberId"]
comment_dict["RMemberName"] = comment["RMemberName"]
comment_dict["replydate"] = comment["replydate"]
comment_dict["ReplyId"] = comment["ReplyId"]
comment_dict["RObjId"] = comment["RObjId"]
comment_dict["RTargetReplyId"] = comment["RTargetReplyId"]
comment_dict["RTargetMemberId"] = comment["RTargetMemberId"]
comment_dict["RReplyDate"] = comment["RReplyDate"]
comment_dict["RContent"] = comment["RContent"]
comment_dict["RFloor"] = comment["RFloor"]
f.write(json.dumps(comment_dict) + "\n")
print(f"**{info}-{each_article_title} completed")
else:
print(f"\tPicture article, passed. URL is {each_article_url}")
if __name__ == '__main__':
main_url = r"https://www.autohome.com.cn"
main_path = r"D:\pycharm\python_work\autohome\汽车之家"
start_time = time.time()
proxies = {'proxy': random.choice(http_ip)}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"Referer": "https://www.autohome.com.cn"
}
car_dict = get_all_cars(main_url, main_path)
# print(car_dict)
# with concurrent.futures.ProcessPoolExecutor(max_workers=8) as p_executor:
# for keys, values in car_dict.items():
# for key, value in values.items():
# file_path = main_path + "\\" + str(keys) + "\\" + key
# info = f"-{keys}-{key}-"
# p_executor.submit(get_each_car_articles, *(main_url, value, file_path, headers, proxies, info))
pool = multiprocessing.Pool()
for keys, values in car_dict.items():
print(keys, values)
for key, value in values.items():
print("\t", key, value)
file_path = main_path + "\\" + str(keys) + "\\" + key
info = f"-{keys}-{key}-"
pool.apply_async(get_each_car_articles, args=(main_url, value, file_path, headers, proxies, info))
pool.close()
pool.join()
end_time = time.time()
print("##########已完成##########")
print(f"spend time {end_time-start_time}")






