如:深圳龙岗区中海信创新产业城15栋(距离地铁10号线凉帽山地铁站D出口30米) 这个字符串 跟表里的所有地址信息做相似度计算 输出对应匹配度最高的字符串跟数值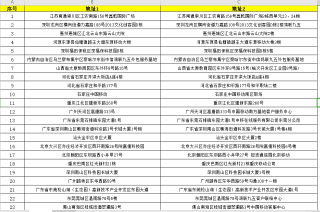

将获取到的地址信息跟Excle表中的所有地址信息做相似度计算

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新
 Jason Ho 2021-07-27 11:47关注
Jason Ho 2021-07-27 11:47关注# -*- coding: utf-8 -*- import jieba import numpy as np import re def get_word_vector(s1,s2): """ :param s1: 句子1 :param s2: 句子2 :return: 返回句子的余弦相似度 """ # 分词 cut1 = jieba.cut(s1) cut2 = jieba.cut(s2) list_word1 = (','.join(cut1)).split(',') list_word2 = (','.join(cut2)).split(',') # 列出所有的词,取并集 key_word = list(set(list_word1 + list_word2)) # 给定形状和类型的用0填充的矩阵存储向量 word_vector1 = np.zeros(len(key_word)) word_vector2 = np.zeros(len(key_word)) # 计算词频 # 依次确定向量的每个位置的值 for i in range(len(key_word)): # 遍历key_word中每个词在句子中的出现次数 for j in range(len(list_word1)): if key_word[i] == list_word1[j]: word_vector1[i] += 1 for k in range(len(list_word2)): if key_word[i] == list_word2[k]: word_vector2[i] += 1 # 输出向量 print(word_vector1) print(word_vector2) return word_vector1, word_vector2 def cos_dist(vec1,vec2): """ :param vec1: 向量1 :param vec2: 向量2 :return: 返回两个向量的余弦相似度 """ dist1=float(np.dot(vec1,vec2)/(np.linalg.norm(vec1)*np.linalg.norm(vec2))) return dist1 def filter_html(html): """ :param html: html :return: 返回去掉html的纯净文本 """ dr = re.compile(r'<[^>]+>',re.S) dd = dr.sub('',html).strip() return dd if __name__ == '__main__': s1="很高兴见到你" s2="我也很高兴见到你" vec1,vec2=get_word_vector(s1,s2) dist1=cos_dist(vec1,vec2) print(dist1)本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2025-09-23 20:00QQ58850198的博客 基于web的大学生返乡回校统计实时查询在设计中采用“自下而上”的思想,在大学生返乡回校统计实时查询系统模块中实现了个人中心、学生管理、学院信息管理、物品分类管理、核酸信息管理、防疫物品管理、物品申领管理...
- 2020-03-18 12:45筱程技术的博客 同时,当用户发起计算请求时,系统会根据用户距离计算中心的“距离”,自动将用户的请求适配到距离用户最近的计算集群上,以便用户可以更快速地获取计算结果,提升用户的计算体验。 在教学管理方面,平台自带人工智能...
- 2020-03-18 12:44筱程技术的博客 同时,当用户发起计算请求时,系统会根据用户距离计算中心的“距离”,自动将用户的请求适配到距离用户最近的计算集群上,以便用户可以更快速地获取计算结果,提升用户的计算体验。 在教学管理方面,平台自带人工智能...
- 2020-03-18 12:44筱程技术的博客 同时,当用户发起计算请求时,系统会根据用户距离计算中心的“距离”,自动将用户的请求适配到距离用户最近的计算集群上,以便用户可以更快速地获取计算结果,提升用户的计算体验。 在教学管理方面,平台自带人工智能...
- 2020-03-18 12:43筱程技术的博客 同时,当用户发起计算请求时,系统会根据用户距离计算中心的“距离”,自动将用户的请求适配到距离用户最近的计算集群上,以便用户可以更快速地获取计算结果,提升用户的计算体验。 在教学管理方面,平台自带人工智能...
- 没有解决我的问题, 去提问

问题事件
 系统已结题
8月4日
系统已结题
8月4日 已采纳回答
7月27日
已采纳回答
7月27日-
创建了问题
7月27日