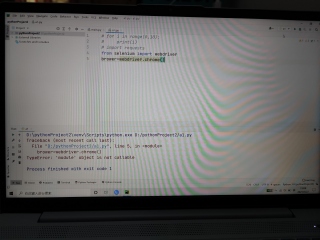

网络爬虫,下载好了chromedriver为什么会报错?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新


- 2025-05-19 17:49kkk_m1的博客 本文详细介绍了如何下载、配置和使用ChromeDriver以配合Selenium进行自动化测试。首先,通过查看Chrome浏览器的版本号,下载与之匹配的ChromeDriver版本,推荐使用国内镜像站点以提高下载速度。接着,解压下载的驱动...
- 2019-09-04 11:07肉装法师的博客 第一次玩selenium+chromedriver 拿度娘玩玩 #驱动浏览器webdriver 不通浏览器有不同的类 from selenium import webdriver driver_path = r"D:\Program\chromedriver\chromedriver.exe" # 驱动google浏览器 用的是...
- 2020-09-17 14:55本文将详细介绍如何使用Python结合Selenium和ChromeDriver实现无头爬虫,并下载文件。 #### 安装与配置 ##### 1. 安装Chrome 首先,我们需要安装Google Chrome。这里以Linux环境为例: ```bash wget ...
- 2023-07-07 11:28云晓-的博客 chromedriver下载与安装方法
- 2020-03-23 10:10逻辑howe的博客 chromedriver版本及使用问题 chromedriver没有win64版本?...笔者练习网络爬虫使用selenium时: from selenium import webdriver driver = webdriver.Chrome() driver.get("http://www.santostang.com/20...
- 2026-01-04 02:15携程邮轮的博客 面对ChromeDriver下载失败、版本不匹配等问题,通过本地化部署、版本管控和脚本化管理,实现稳定可靠的浏览器自动化。掌握驱动与浏览器的版本对应关系,结合校验、软链接和启动脚本,构建可复用的离线运行环境,适用...
- 2026-01-05 17:14序雨的博客 面对Chrome频繁更新导致Chromedriver匹配困难的问题,传统爬虫易因网页结构变化而失效。借助GLM-4.6V-Flash-WEB多模态模型,通过截图理解网页内容,智能识别最新下载链接,摆脱对HTML结构的依赖,实现高鲁棒性自动化...
- 2025-07-30 14:23fsnine的博客 网络爬虫(Web Crawler)是一种自动抓取互联网信息的程序,它能够高效地从海量网页中提取有价值的数据。作为数据采集的利器,爬虫技术在数据分析、搜索引擎、价格监控等...本文将带你全面了解Python网络爬虫的开发。
- 2026-01-03 14:24影评周公子的博客 在集成LoRA训练系统时,Chromedriver网络问题常导致CI/CD失败。本文提出通过接口级测试替代UI自动化,结合Playwright与分层架构,实现稳定高效的工程化部署,真正摆脱外部驱动依赖,提升自动化测试可靠性。
- 2022-10-22 07:00艾派森的博客 本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。
- 2021-01-11 18:47BoBo玩ROS的博客 1.2 网络爬虫 2 1.3 数据可视化 2 1.4 Python环境介绍 2 1.4.1 简介 2 1.4.2 特点 3 1.5 扩展库介绍 3 1.5.1 安装模块 3 1.5.2 主要模块介绍 3 ① pandas模块 3 ② requests模块 4 ③ bs4模块 4 ④ selenium模块 4 ...
- 2022-03-14 17:50园游会永不打烊.的博客 今天首次使用selenium爬虫,需要下载chrome浏览器,以及对应的驱动: 1.下载chrome浏览器 点我下载 2.安装chromedriver驱动 点我下载 查看对应的版本方法: 通过 桌面 ,属性,查看文件位置 我的浏览器安装地址是C:\...
- 2023-06-13 16:50TTTALK的博客 python爬虫资源抓取--urllib/requests/requests-html、正则表达式、数据解析-Beautiful Soup/lxml/selectolax、自动化爬虫--selenium、爬虫框架--Scrapy/pyspider、模拟登录与验证码识别、autoscraper
- 2023-05-19 23:17爱吃饼干的小白鼠的博客 今天,主要和大家讲解了如何正确安装好Chrome 浏览器并配置好ChromeDriver。另外,还教大家如何正确安装好 Python 的 Selenium 库。
- 2024-08-28 01:52天涯幺妹的博客 在互联网上存在大量需要登录才能访问的网站,要爬取这些网站,就需要学习爬虫的模拟登录。对于一个需要登录才能访问的网站,它的页面在登录前和登录后可能是不一样的。
- 2021-08-31 23:01hwwaizs的博客 使用爬虫程序会给服务器造成一定的压力,维护者会制定一系列的反爬机制,二者进行相互切磋。 爬虫建议 尽量减少请求次数,程序执行速度比较快,会对服务器产生压力,管理者会指定一系列的反爬机制进行制衡,可以将...
- 2021-06-07 22:19思想流浪者的博客 一、什么是AJAX AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML。过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行...
- 2026-01-05 17:33红廉骑士兽的博客 Chromedriver下载不稳定、版本难匹配的问题困扰自动化开发。GLM-4.6V-Flash-WEB提供新思路:无需驱动,通过截图理解页面,像人一样‘看图操作’。模型本地运行,响应迅速,避开了网络依赖与反爬机制,为测试、RPA等...
- 2026-01-06 00:45如水蜜的博客 Chrome浏览器更新后常因驱动版本不匹配导致自动化失败,传统爬虫和Selenium维护成本高。借助GLM-4.6V-Flash-WEB多模态模型,只需上传网页截图并提问,AI即可识别官方下载地址,绕过广告干扰与反爬机制,实现高效精准...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
8月4日
系统已结题
8月4日 已采纳回答
7月27日
已采纳回答
7月27日-
创建了问题
7月27日