

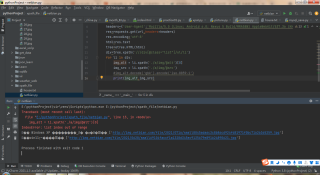
代码如下:爬取图片名和图片地址
import requests
from lxml import etree
if __name__ == '__main__':
url='http://www.netbian.com/fengjing/'
headers={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Mobile Safari/537.36'}
res=requests.get(url,headers=headers)
res.encoding='utf-8'
html=res.text
tree=etree.HTML(html)
div=tree.xpath('///div[@class="list"]/ul/li')
for li in div:
img_alt = li.xpath('./a/img/@alt')[0]
img_src = li.xpath('./a/img/@src')
#img_alt.decode('gbk').encode('iso-8859-1')
print(img_alt,img_src)
这个也是答案部分正确后面报错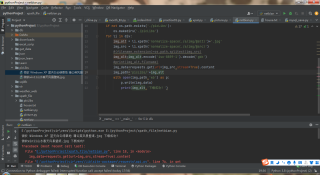
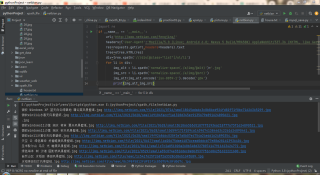
原因是这一页第三张图片没读出alt和src(第三行只有一个.jpg)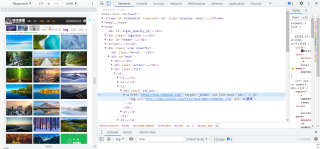
我看第三个li挺正常啊,为什么我的代码读不出来






