

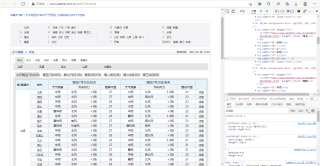
循坏里面就打印不出结果是怎么回事呢?
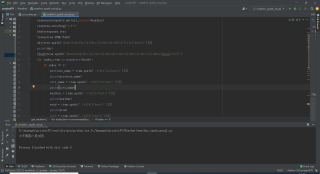
代码如下:想要打印城市,天气等信息
import requests
from lxml import etree
def get_weather():
url = 'http://www.weather.com.cn/textFC/hb.shtml'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'}
response=requests.get(url,headers=headers)
response.encoding='utf-8'
html=response.text
tree=etree.HTML(html)
day=tree.xpath('/html/body/div[4]/div[2]/div/div/ul[2]/li[1]/text()')[0]
print(day)
tbody=tree.xpath('/html/body/div[4]/div[2]/div/div/div[2]/div[1]/div[1]/table/tbody/tr[3]')
for index,item in enumerate(tbody):
if index == 0:
province_name = item.xpath('./td[1]/a/text()')[0]
print(province_name)
city_name = item.xpath('./td[2]/a/text()')[0]
print(city_name)
weather = item.xpath('./td[3]/text()')[0]
print(weather)
wind = item.xpath('./td[4]//text()')[0]
print(wind)
high = item.xpath('./td[5]/text()')[0]
weather_night = item.xpath('./td[6]/text()')[0]
wind_night = item.xpath('./td[7]//text()')[0]
low = item.xpath('./td[8]/text()')[0]
#print(province_name)
else:
city_name=item.xpath('./td[1]/text()')[0]
weather = item.xpath('./td[2]/text()')[0]
wind = item.xpath('./td[3]//text()')[0]
high = item.xpath('./td[4]/text()')[0]
weather_night = item.xpath('./td[5]/text()')[0]
wind_night = item.xpath('./td[6]//text()')[0]
low = item.xpath('./td[7]/text()')[0]
print(city_name, weather, wind, high, weather_night, wind_night, low)
if __name__ == '__main__':
get_weather()







