scrapy 这个端口什么意思,我电脑没有这个端口也能抓取到数据。这个端口作用是什么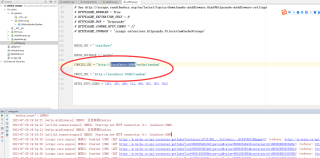

scrapy 这个端口什么意思,我电脑没有这个端口也能抓取到数据。这个端口作用是什么

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2023-11-01 17:54本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端...
- 2024-04-04 12:04本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端接受...
- 2023-06-15 15:25本项目爬虫端和网站后台采用Python语言开发,其中爬虫利用的是Scrapy框架可以轻松实现网站数据的抓取,抓取到的兼职信息直接保存到mysql数据库中,前端采用Vue开发,实现了前后端分离的模式,前端请求Django后端...
- 2025-08-12 13:19Scrapy作为Python编写的开源和协作的爬虫框架,能够帮助开发者快速抓取网站数据。然而,在实际操作过程中,遇到网站的反爬机制是常有的事,而使用代理则是绕过这些限制的一种有效方法。本篇指南将详细介绍如何在...
- 2020-11-21 00:04weixin_39766071的博客 src) img_count = img_count + 1 # 替换掉抓取的文章中的video标签src是否含有 绝对地址 data_video = page.find_all('video', attrs={'src': True}) data_video_len = len(data_video) # 获取到一共有多少个图片 ...
- 2024-04-08 22:26Scrapy-Redis是一个将Scrapy框架与Redis数据库相结合的分布式爬虫模板,它允许你在多个机器上并行地运行爬虫,从而提高了数据抓取的效率。本项目提供了完整的源码和项目说明,适合用于Python编程的学生进行毕业设计...
- 2025-04-23 21:12缑宇澄的博客 通过分布式架构,不同节点可以同时对不同的URL进行抓取,充分利用多台机器的计算资源和网络带宽,实现大规模数据的高效采集。与传统单节点爬虫相比,分布式爬虫在处理海量数据时具有明显的性能优势,并且具备更好的...
- 2024-02-23 18:09学习这个项目,你可以深入理解如何利用Scrapy和Redis构建分布式爬虫,掌握如何处理大规模数据抓取,以及如何在分布式环境中优化爬虫性能。这将有助于提升你在数据分析、Web抓取、搜索引擎构建等相关领域的专业技能。
- 2023-01-30 20:07Scrapy是一个用Python编写的开放源代码框架,专为数据抓取和数据提取而设计,常用于网页抓取和Web抓取项目。在这个“爬虫python入门用python的scrapy框架爬取网站的代理ip”的案例中,我们将深入探讨如何利用Scrapy...
- 2025-04-22 10:39Python爬虫笔记内容知识点: 一、爬虫基础 爬虫是一种自动化程序,主要功能是请求网站并提取数据。它遵循统一资源定位符(URL)的规则来定位互联网上的资源。URL的一般格式包含协议类型、服务器地址、端口号、文件...
- 没有解决我的问题, 去提问


问题事件
 已结题
(查看结题原因) 10月26日
已结题
(查看结题原因) 10月26日-
已采纳回答
10月26日
-
创建了问题
7月29日