
我提取所有的PDF中的表格,然后选择需要的数据,存放到excel。 但是现在我把需要的数据遍历出来了,类型为多组的list。存放到excel时,只有最后一组list的数据

我提取所有的PDF中的表格,然后选择需要的数据,存放到excel。 但是现在我把需要的数据遍历出来了,类型为多组的list。存放到excel时,只有最后一组list的数据
 分享
分享
to_excel()函数在每次循环中都写入一次,会覆盖写入,结果就是最后一组的数据。如果要获取全部的,可以在循环中用append方法,写成一个整的数据框,然后在循环外用to_excel写入。
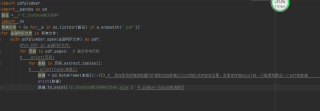
import pdfplumber
import pandas as pd
path = 'F:\data_pro'
import os
fs=[a for a in os.listdir(path) if a.endswith('.pdf')]
df=pd.DataFrame()
for f in fs[:3]:
with pdfplumber.open(os.path.join(path,f)) as pdf:
for page in pdf.pages:
for table in page.extract_tables():
data=pd.DataFrame(table)
if len(data)!=0:
df=df.append(data,ignore_index=False)
df.to_excel(os.path.join(path, f'merge_tbl.xlsx'), index=False)
 系统已结题
8月10日
系统已结题
8月10日 已采纳回答
8月2日
修改了问题
8月1日
修改了问题
8月1日
已采纳回答
8月2日
修改了问题
8月1日
修改了问题
8月1日

