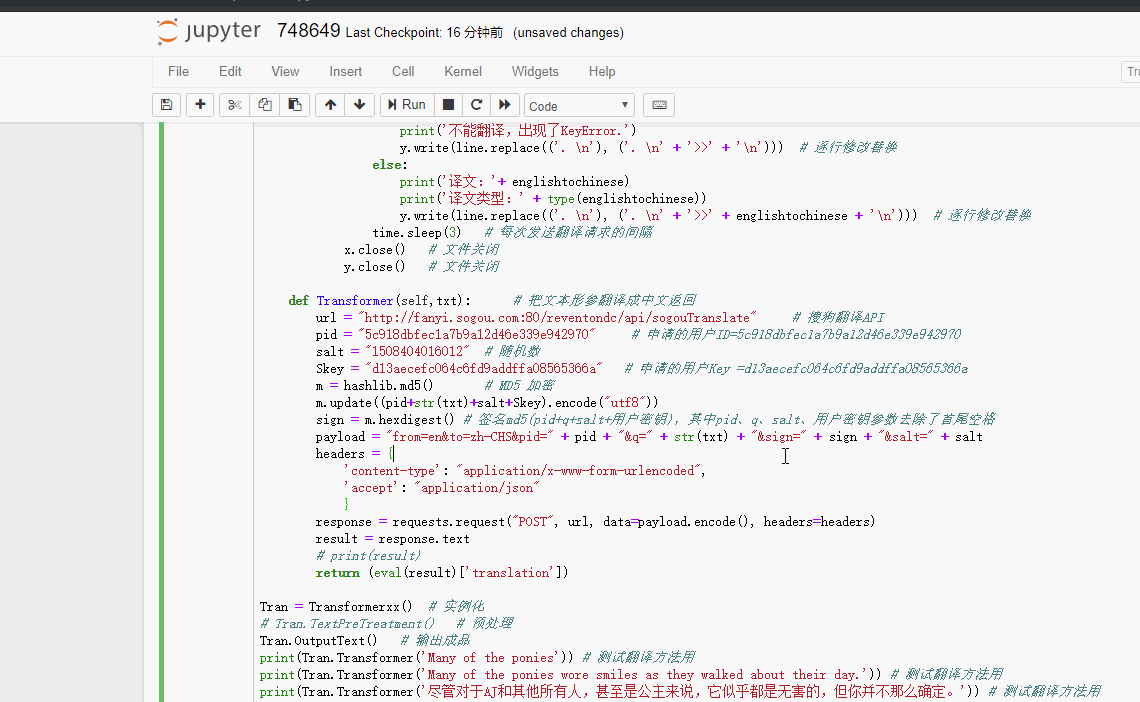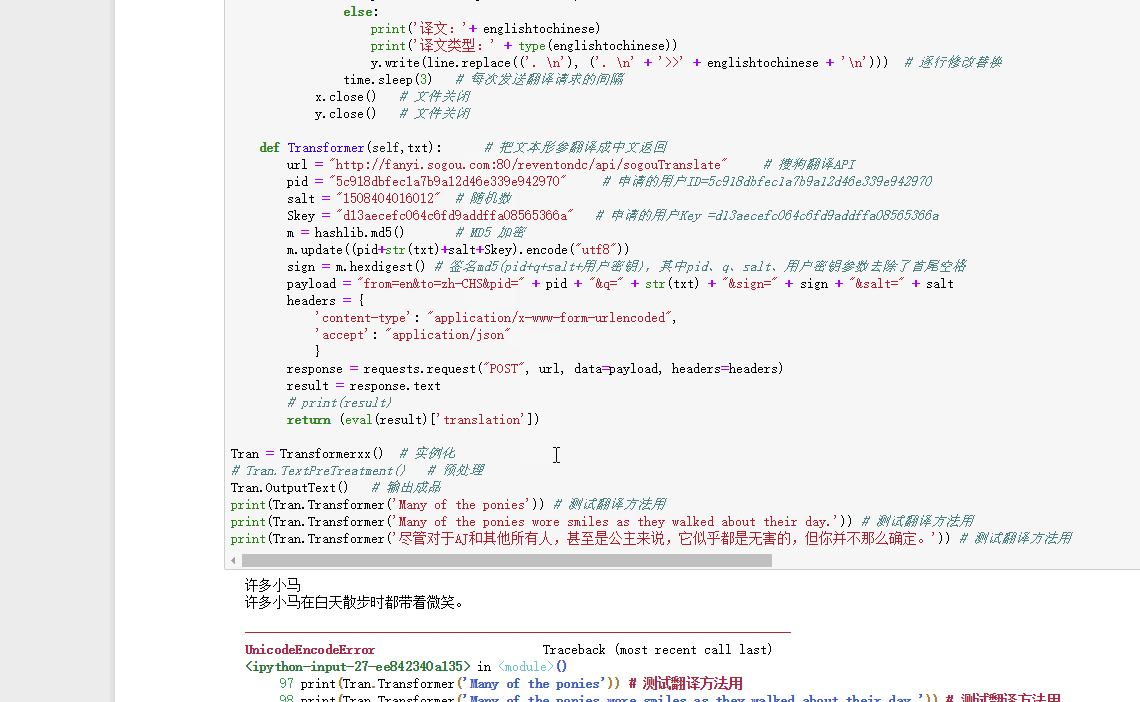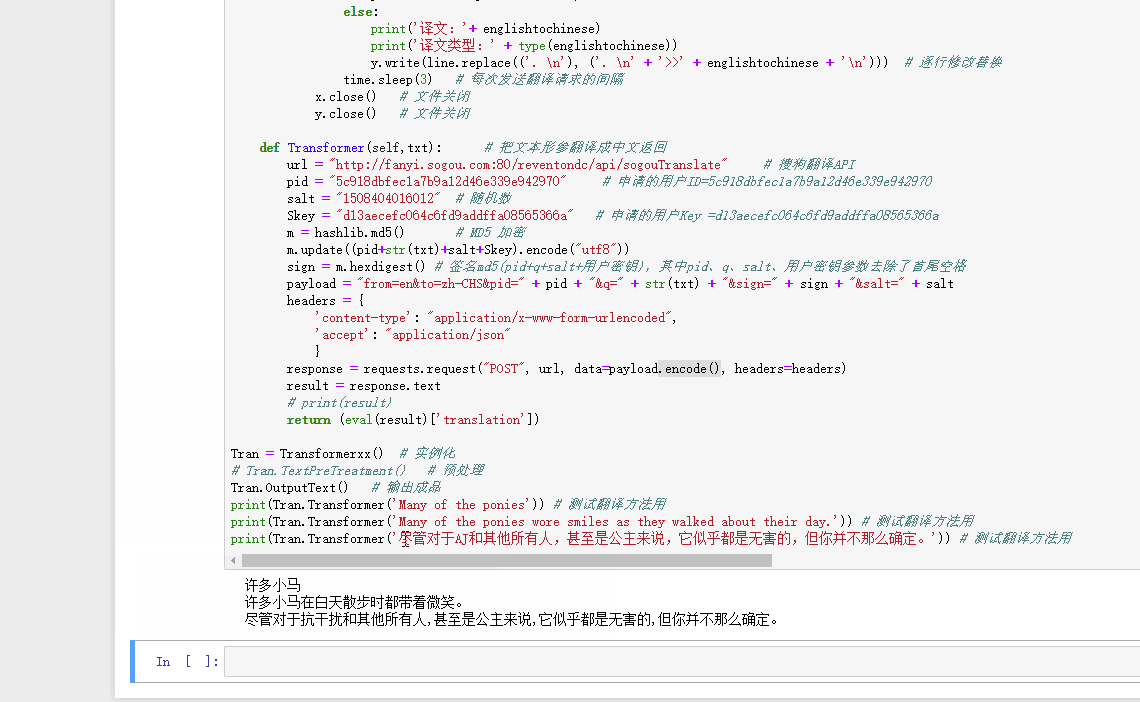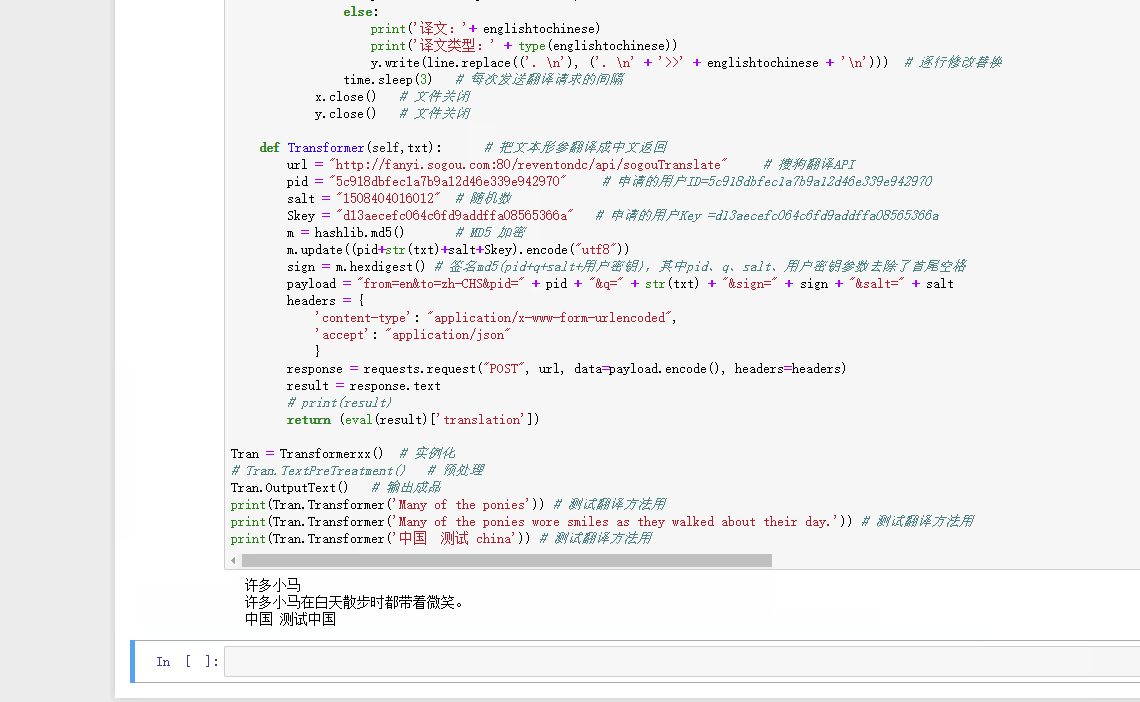
该脚本的作用是把英文文档变成中英文混合模式,以便翻译使用。但运行结果却没有一句能翻译成功,全都是KeyError,最后就是UnicodeEncodeError。
# -*- coding: utf-8 -*-
# Python版本:3.6,搜狗翻译API,ID和Key均可用。
# 该脚本作用:把从FF下载的文本文档按句回车,再把上面句的机翻结果自动插入下面。
"""
例:
处理前:A Word of Caution (1).txt
You are Twilight, and today in a difficult situation. Applejack has adopted some creature from the Everfree forest. And while it seems harmless enough to AJ and everyone else, even the Princess, you're not so sure. Never before has anybody seen anything like him.
处理后:out_A Word of Caution (1).txt
You are Twilight, and today in a difficult situation.
>>你是暮光之城,今天处境艰难。
Applejack has adopted some creature from the Everfree forest.
>>Applejack采用了Everfree森林中的一些生物。
And while it seems harmless enough to AJ and everyone else, even the Princess, you're not so sure.
>>尽管对于AJ和其他所有人,甚至是公主来说,它似乎都是无害的,但你并不那么确定。
Never before has anybody seen anything like him.
>>从来没有人见过像他这样的人。
"""
import requests
import hashlib
import os
import time
class Transformerxx(object):
def __init__(self):
self.top_dir = os.path.dirname(os.path.abspath('Runner v0.01.py'))
self.workingDir = self.top_dir + '\\FirstText\\' # 待翻译文件存放目录
self.outputDir = self.top_dir + '\\TransedText\\' # 翻译中文件存放目录
self.znputDir = self.top_dir + '\\ZhcnText\\' # 处理完文件存放目录
self.input_dirs = os.listdir(self.workingDir) # 待翻译文件名列表
self.output_dirs = os.listdir(self.outputDir) # 翻译后文件名列表
self.znput_dirs = os.listdir(self.znputDir) # 处理完文件名列表
def TextPreTreatment(self): # 本函数的用处是预处理,把待处理的文本文件按照 '. '来分段。以便逐行读取并翻译
'''
思路修正
在预处理之中,应该可以直接调用翻译函数/方法,
从文本中读取的每一行都要进行翻译处理,
再以“>>机翻文本\n”的方式加到当前行后面。
最终输出结果
'''
# print(self.input_dirs) # 中间结果检查
# print('*') # 中间结果检查
# print(self.output_dirs) # 中间结果检查
for name in self.input_dirs:
print('源文件:' + name)
outname = 'out_' + name
print('输出文件' + outname)
x = open(self.workingDir + name,'r',encoding="utf-8") # 打开文件
y = open(self.outputDir + outname,'w',encoding="utf-8") # 写入文件
for line in x:
y.write(line.replace('. ','. \n')) # 逐行修改替换
x.close() # 文件关闭
y.close() # 文件关闭
def OutputText(self):
for name in self.output_dirs:
x = open(self.outputDir + name,'r',encoding="utf-8") # 打开文件
y = open(self.znputDir + name,'w',encoding="utf-8") # 写入文件
for line in x:
print('当前翻译行:'+ line)
try:
englishtochinese = Transformerxx().Transformer(line) # 本程序疑问处
except KeyError:
print('不能翻译,出现了KeyError.')
y.write(line.replace(('. \n'), ('. \n' + '>>' + '\n'))) # 逐行修改替换
else:
print('译文:'+ englishtochinese)
print('译文类型:' + type(englishtochinese))
y.write(line.replace(('. \n'), ('. \n' + '>>' + englishtochinese + '\n'))) # 逐行修改替换
time.sleep(3) # 每次发送翻译请求的间隔
x.close() # 文件关闭
y.close() # 文件关闭
def Transformer(self,txt): # 把文本形参翻译成中文返回
url = "http://fanyi.sogou.com:80/reventondc/api/sogouTranslate" # 搜狗翻译API
pid = "5c918dbfec1a7b9a12d46e339e942970" # 申请的用户ID=5c918dbfec1a7b9a12d46e339e942970
salt = "1508404016012" # 随机数
Skey = "d13aecefc064c6fd9addffa08565366a" # 申请的用户Key =d13aecefc064c6fd9addffa08565366a
m = hashlib.md5() # MD5 加密
m.update((pid+str(txt)+salt+Skey).encode("utf8"))
sign = m.hexdigest() # 签名md5(pid+q+salt+用户密钥),其中pid、q、salt、用户密钥参数去除了首尾空格
payload = "from=en&to=zh-CHS&pid=" + pid + "&q=" + str(txt) + "&sign=" + sign + "&salt=" + salt
headers = {
'content-type': "application/x-www-form-urlencoded",
'accept': "application/json"
}
response = requests.request("POST", url, data=payload, headers=headers)
result = response.text
# print(result)
return (eval(result)['translation'])
Tran = Transformerxx() # 实例化
# Tran.TextPreTreatment() # 预处理
Tran.OutputText() # 输出成品
# print(Tran.Transformer('Many of the ponies')) # 测试翻译方法用
# print(Tran.Transformer('Many of the ponies wore smiles as they walked about their day.')) # 测试翻译方法用
UnicodeEncodeError: 'latin-1' codec can't encode character '\u2019' in position 156: Body ('’') is not valid Latin-1. Use body.encode('utf-8') if you want to send it encoded in UTF-8.