已经配置了hadoop的环境变量,也source过了,但是只要不在hadoop/bin下面使用hdfs dfs -ls / 查询到的就是本地文件目录,并且报错:
Warning: fs.defaultFS is not set when running "ls" command.
如图: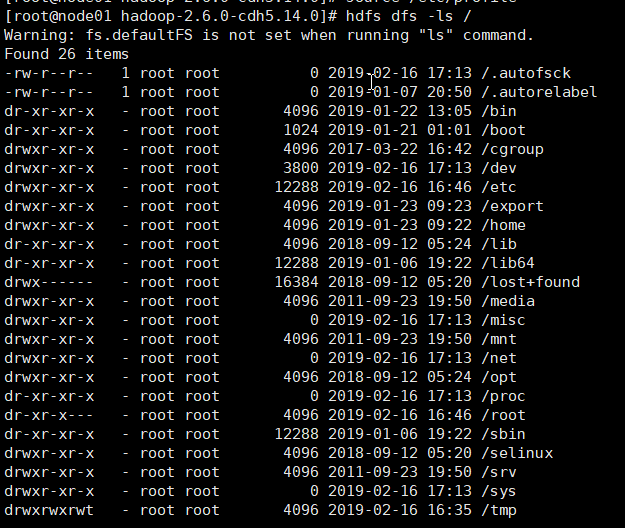
但如果在bin目录下,显示正确,如图: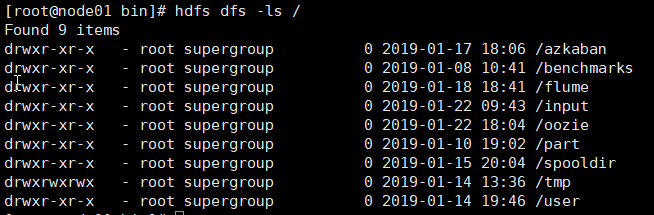
环境变量如图:
上网查了有人说core-site.xml有问题,我不是这个问题,配置文件如下: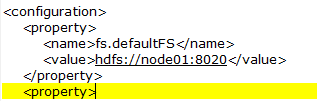
请问有人知道这是怎么回事吗?

已经配置了hadoop的环境变量,也source过了,但是只要不在hadoop/bin下面使用hdfs dfs -ls / 查询到的就是本地文件目录,并且报错:
Warning: fs.defaultFS is not set when running "ls" command.
如图:
但如果在bin目录下,显示正确,如图:
环境变量如图:
上网查了有人说core-site.xml有问题,我不是这个问题,配置文件如下:
请问有人知道这是怎么回事吗?
 分享
分享
使用which hadoop和which hdfs查看是否指向正确位置,若不是,则删掉错误位置处的文件,重新source,然后一切正常
分享 Hadoop执行hdfs dfs -ls /报错: Call From master/192.168.88.108 to slave1:9820 failed on connection except
Hadoop执行hdfs dfs -ls /报错: Call From master/192.168.88.108 to slave1:9820 failed on connection except
