我想要爬取lol官网的一些特定图片,不管是英雄图标还是活动图标:
由于电脑截图出了点问题,所以只能手机拍照,不好意思。
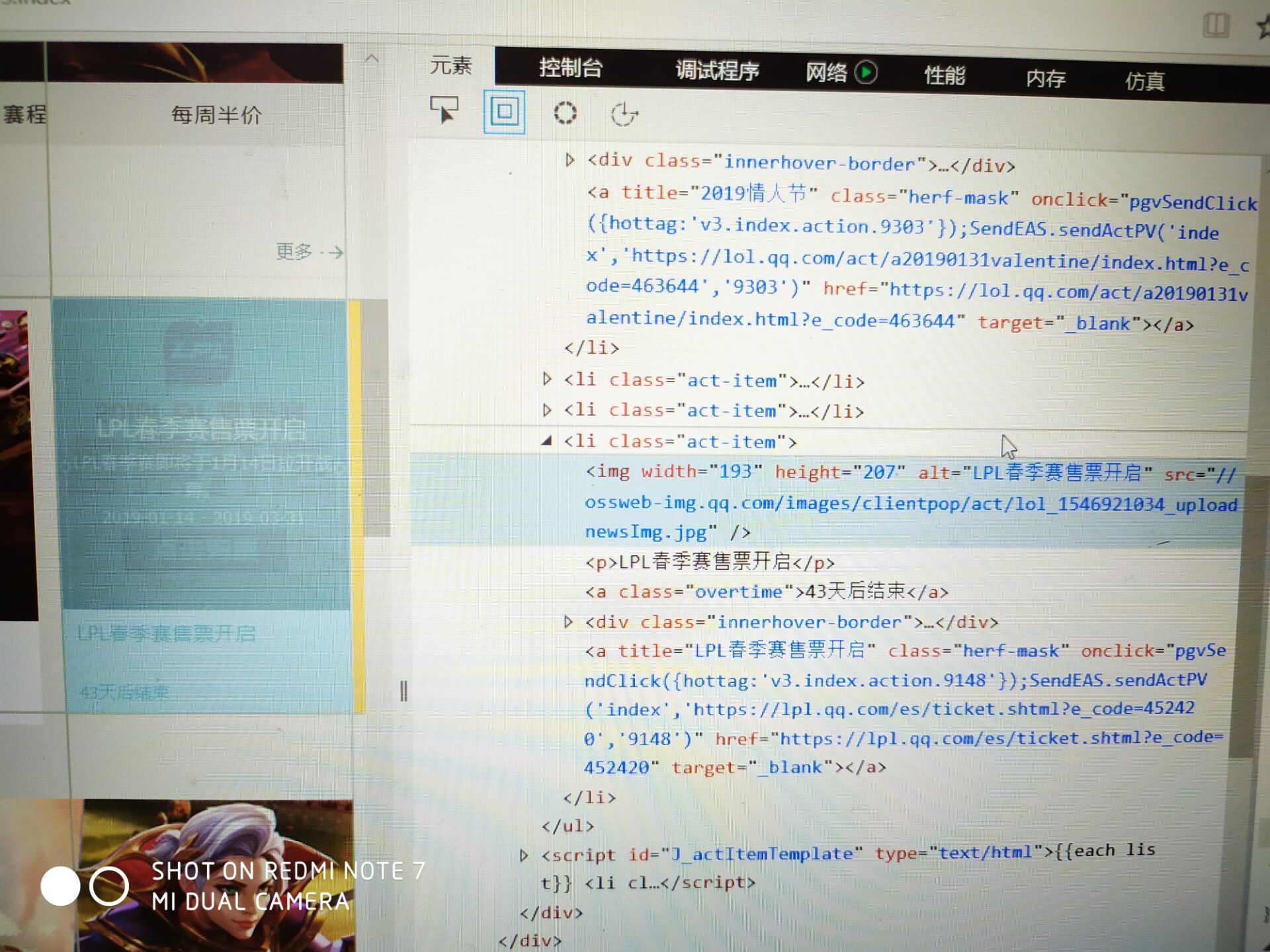
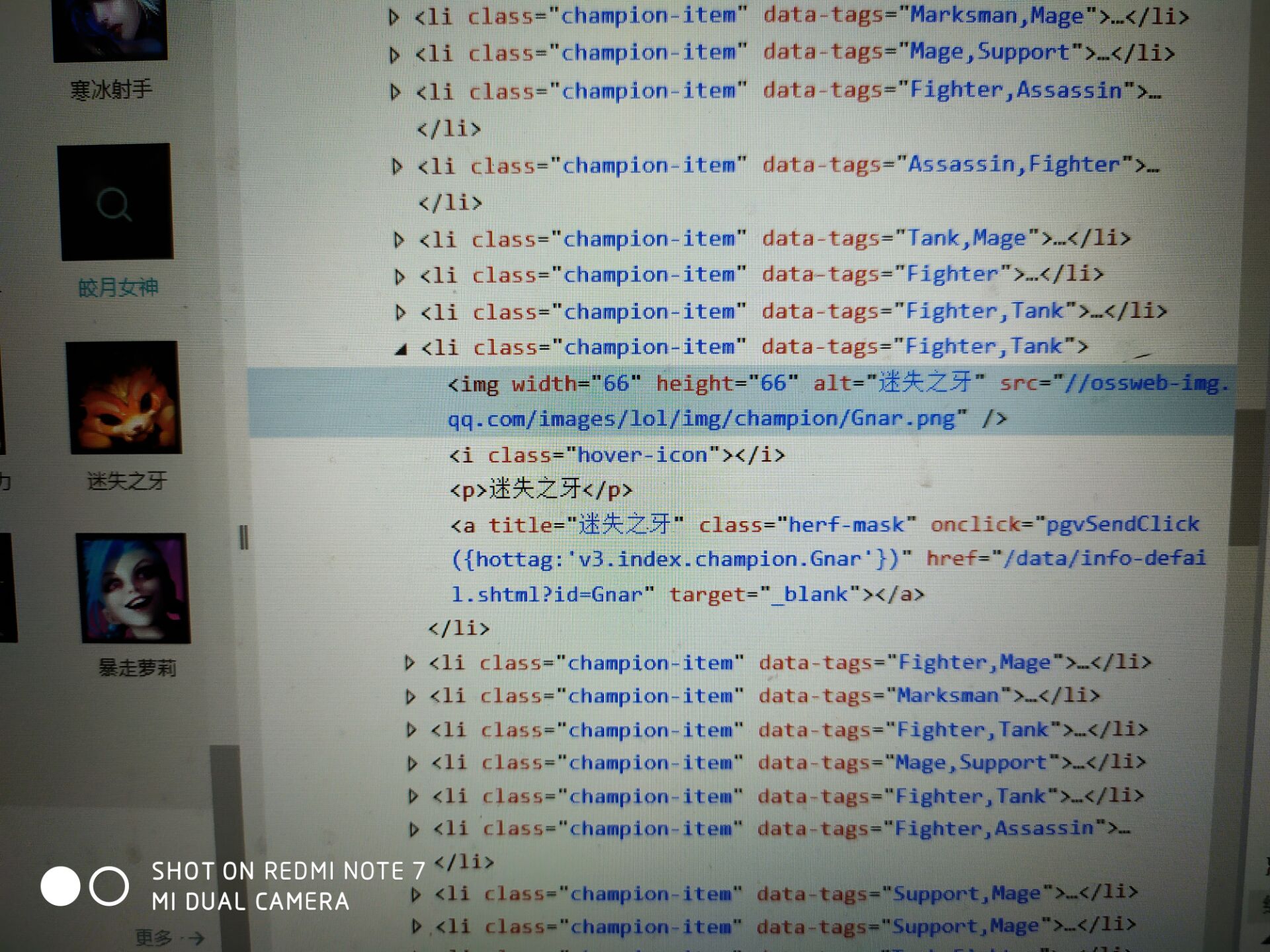
可以看到这个网页里面有很多这种图片,而且sec都是有类似的格式,以//ossweb-img.qq.com开头
我想爬取这些图片
我的代码:
import os
from urllib.request import urlopen
from urllib.request import urlretrieve
from bs4 import BeautifulSoup
import re
baseURL="http://lol.qq.com/main.shtml?ADTAG=lolweb.v3.index"
html=urlopen("https://lol.qq.com/main.shtml?ADTAG=lolweb.v3.index")
bsobj=BeautifulSoup(html,"lxml")
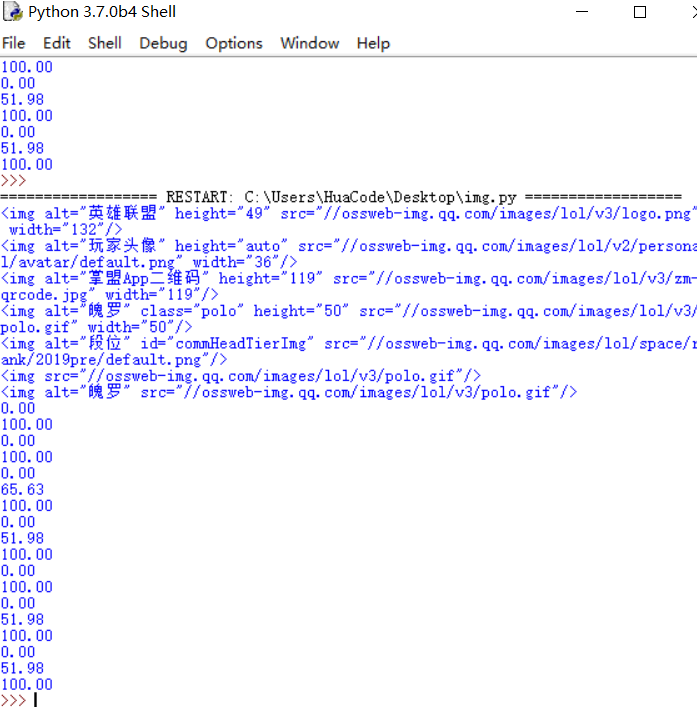
downloadlist=bsobj.findAll(src=re.compile(".*ossweb-img.qq.com.*png"))
print(downloadlist)
a=1
def cbk(a,b,c): 下载进度函数
per=100.0*a*b/c
if per>=100:
per=100
print ('%.2f'%per)
for download in downloadlist:
fileURL=download['src']
if fileURL is not None:
fileURL="http:"+fileURL
print(fileURL)
urlretrieve(fileURL,"download"+str(a)+".png",cbk)
a=a+1
但是它只下载了该网页第一个div容器里的图片,其他的都没下载,这时为什么