请问以下impala查询该如何优化,查询速度有点慢(5s以上)
impala查询语句:
select case when t.nl>=18 and t.nl<=25 then '18-25岁'
when t.nl>=26 and t.nl<=32 then '26-32岁'
when t.nl>=33 and t.nl<=40 then '33-40岁'
when t.nl>=41 and t.nl<=48 then '41-49岁'
when t.nl>=49 and t.nl<=55 then '49-55岁'
end as nld,count(1) jls
from
(select
case when length(sfzh)=18 then
cast(from_unixtime(unix_timestamp(xxrq,'yyyy-MM-dd'),'yyyy') as int)-cast(substr(sfzh,7,4) as int)
else cast(from_unixtime(unix_timestamp(xxrq,'yyyy-MM-dd'),'yyyy') as int)-cast(concat('19',substr(sfzh,7,2)) as int)
end as nl,xxrq,sfzh from hbase_impala.impala_table39119_1550771711308
where sfzh is not null and year(now())-year(xxrq) <=4
) t
where t.nl>=18 and t.nl<=55 group by nld order by nld;
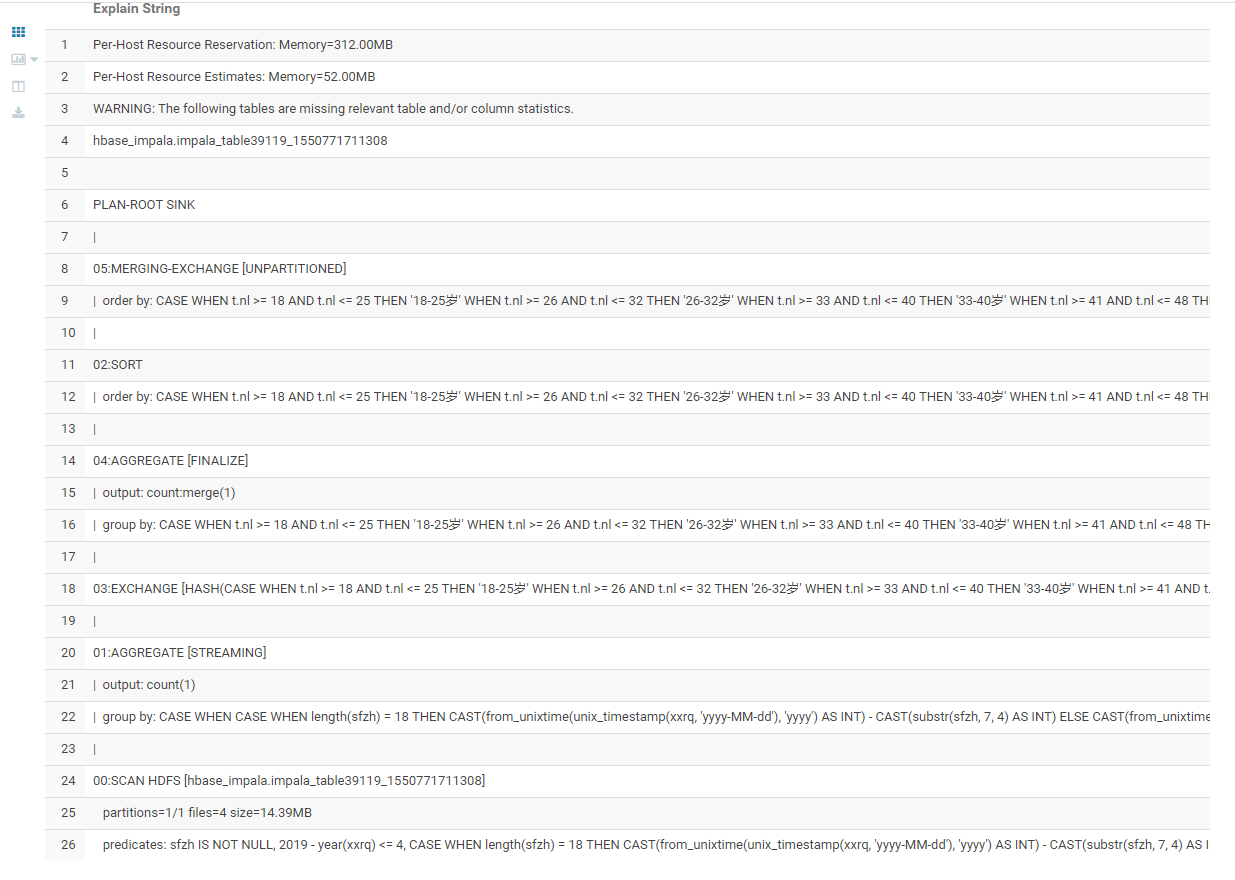
explain结果: