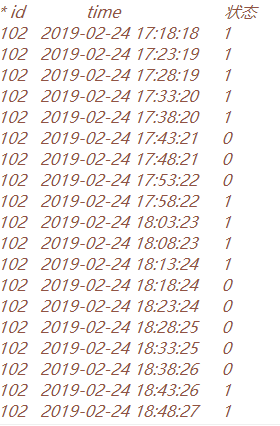
如果可以的话,我建议您用UDF更加方便,如果非要用hql呢,下面是我的想法
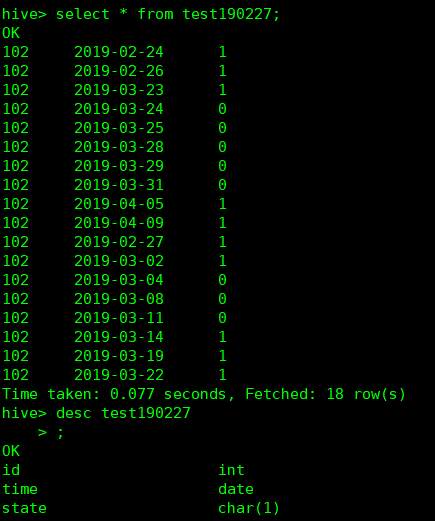
首先,这是我准备的测试数据,如图,当中,方便计算,我就把时间那一列改了成了‘天’的粒度。
然后,我增加一个自增序列的字段,别名是 num,如图
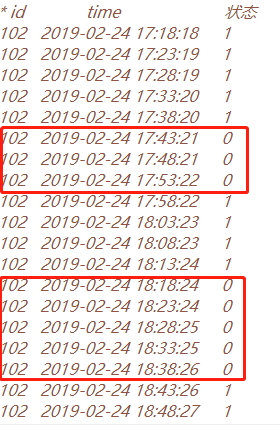
在这个基础上呢,我取出状态是‘0’的数据,如图
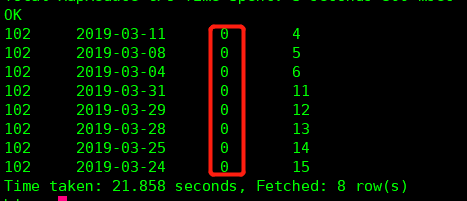
再在这个基础上,再增加一个自增序列字段,别名是 num2,如图
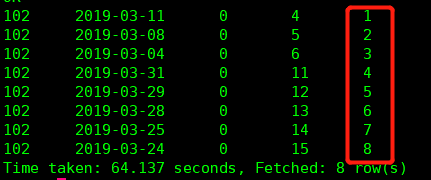
数据处理到这里,帅哥,你是否有一点想法了呢?
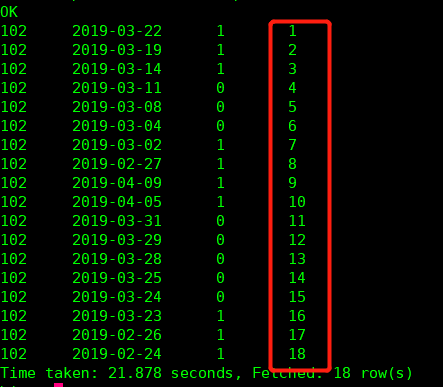
那我继续,再增加一个字段,别名是 groups,意为分组,逻辑就是 num - num2 !如图
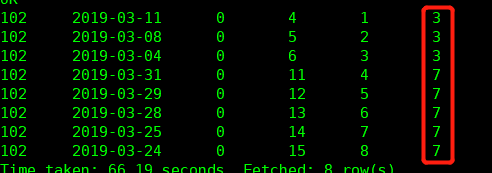
现在感觉怎么样?接下来就按照这个groups分组,取每组最大值和最小值相减,interval,完活!最后再来个图
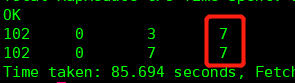
drop table test190227;
create table test190227
(
id int,
time date,
state char(1)
);
set hive.exec.mode.local.auto=true;
insert into test190227 select 102,to_date('2019-02-24'),'1';
insert into test190227 select 102,to_date('2019-02-26'),'1';
insert into test190227 select 102,to_date('2019-02-27'),'1';
insert into test190227 select 102,to_date('2019-03-02'),'1';
insert into test190227 select 102,to_date('2019-03-04'),'0';
insert into test190227 select 102,to_date('2019-03-08'),'0';
insert into test190227 select 102,to_date('2019-03-11'),'0';
insert into test190227 select 102,to_date('2019-03-14'),'1';
insert into test190227 select 102,to_date('2019-03-19'),'1';
insert into test190227 select 102,to_date('2019-03-22'),'1';
insert into test190227 select 102,to_date('2019-03-23'),'1';
insert into test190227 select 102,to_date('2019-03-24'),'0';
insert into test190227 select 102,to_date('2019-03-25'),'0';
insert into test190227 select 102,to_date('2019-03-28'),'0';
insert into test190227 select 102,to_date('2019-03-29'),'0';
insert into test190227 select 102,to_date('2019-03-31'),'0';
insert into test190227 select 102,to_date('2019-04-05'),'1';
insert into test190227 select 102,to_date('2019-04-09'),'1';
SELECT
t.id,
t.state,
t.groups,
datediff(max(t.time), min(t.time)) INTERVAL
FROM
(
SELECT
z.*, z.num - z.num2 groups
FROM
(
SELECT
p.*, row_number () over () num2
FROM
(
SELECT
a.*, row_number () over () num
FROM
test190227 a
ORDER BY
num DESC
) p
WHERE
p.state = '0'
) z
) t
GROUP BY
t.id,
t.state,
t.groups;