
一、遇到问题的现象描述
1.1 英文和特殊字符连在一起的的分词,比如 Special Feature Note for T972-SE.pdf
1.2 使用 ik_smart 会直接分词为 t972-se.pdf
1.3 使用 ik_max_word 会分词为:
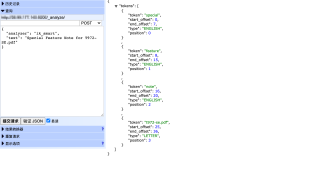
二、希望达到的效果
2.1 要求分词为 t972 和 se,且不分词成单独 t
2.2 使用的 ik 的自定义字典, 将 - 作为单词, 只对 ik_max_word 起作用,对 ik_smart 无效
2.3 要求不能 搜 t 搜出来结果
三、我尝试的解决办法
3.1 我还使用了 字符过滤器 char_filter
3.2 处理了特殊字符,使用的自定义分词器为 my_analyzer,也有分出单个字符
3.3 T972-SE.pdf 把这个当做分隔符,横杠,也试过。
3.4 标准分词器不能对中文分词,也不支持大小写,所以只能用IK。
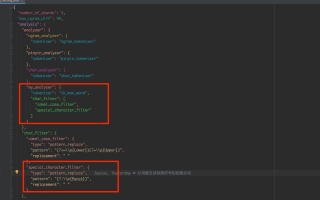
四、操作环境、软件版本
4.1 IK 与 ES,都是6.4.3
4.2 操作系统使用 Linux
五、麻烦看看,如何收费
5.1 我认可知识付费。
5.2 可以根据标准,提供收费方式。







