
网页打开正常的情况:
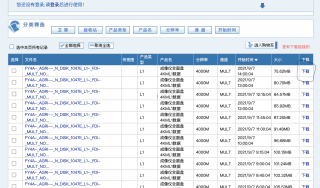
但,自己使用selenium时却没有下载项,都是用的Googal
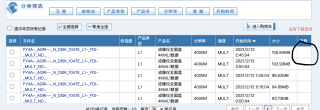
以下是我的代码:
def crawl(a = '2021-02-12',b = '2021-02-12',c = '00:00:00',d = '03:00:00'):
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36')
bro = webdriver.Chrome(executable_path='./chromedriver',options=option)
bro.get('http://satellite.nsmc.org.cn/PortalSite/Data/Satellite.aspx')
a_search = bro.find_element_by_id('txtBeginDate')
a_search.clear()
a_search.send_keys(a)
b_search = bro.find_element_by_id('txtEndDate')
b_search.clear()
b_search.send_keys(b)
c_search = bro.find_element_by_id('txtBeginTime')
c_search.clear()
c_search.send_keys(c)
d_search = bro.find_element_by_id('txtEndTime')
d_search.clear()
d_search.send_keys(d)
sele = bro.find_element_by_id(
'FY4A-_AGRI--_N_DISK_1047E_L1-_FDI-_MULT_NOM_YYYYMMDDhhmmss_YYYYMMDDhhmmss_4000M_V0001.HDF')
sele.click()
time.sleep(5)
search = bro.find_element_by_id('imgSearch')
search.click()
time.sleep(1)
求解答!
在线等
爬取的网站是:
数据下载
http://satellite.nsmc.org.cn/PortalSite/Data/Satellite.aspx







