
2022款美版本田思域掀背车搭载六速手动变速箱_易车视频
https://vc.yiche.com/vplay/2096003.html
爬这个网址里的视频在xhr包里找不到视频链接?

python爬视频xhr找不到链接🌝🌝

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 CSDN专家-showbo 2021-09-11 11:16关注
CSDN专家-showbo 2021-09-11 11:16关注直接在源代码里面,没有使用xhr。有帮助麻烦点个采纳【本回答右上角】,谢谢~~
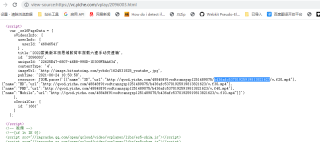
爬取代码如下,前后截取下得到json字符串后处理下
import requests import re import json s=requests.get('https://vc.yiche.com/vplay/2096003.html').text startstr="JSON.parse(" start=s.find(startstr)+len(startstr)+1 end=s.find("'",start) s=s[start:end]#前后截取得到json字符串 data=json.loads(s) for item in data: print(item["name"],item["url"])本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 3无用举报 分享
- 2024-08-18 03:23人生回答机的博客 我整理的一些关于【Python】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://d.51cto.com/Hpqqk2Python 爬虫无 XHR 的实现指南 在现代网站中,数据很多时候并不是直接在 HTML 中呈现的。这些网站...
- 2024-12-09 09:47一个不务正业的程序猿的博客 XHR,全称XMLHttpRequest,是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。它允许网页的JavaScript代码与服务器进行异步通信,即在发送请求后,浏览器不会阻塞用户的后续操作,而是等待服务器响应...
- 2020-11-30 11:11weixin_39620679的博客 找歌名:歌曲名就在这里,它的键是name,XHR是一个字典 需要你一层一层展开:data-song-list-0-name,然后就能看到“知足” json 这里我们要解决的问题是:如何把response对象转成列表/字典呢? 在Python语言当中,...
- 2021-09-19 18:42僭醴。的博客 郑重声明:该文章仅供参考学习,他人不得转载,利用非法手段牟利。...第二步,编写python代码 四.AES加密的的m3u8文件 first.我们需要下载每一集的目录(m3u8文件) second.上代码 这篇文章的由来,是我为.
- 2025-10-20 09:52Datafox(数据狐)的博客 摘要:本文系统介绍了抓包过程中定位接口地址的解决方案。详细讲解了浏览器开发者工具和Fiddler/Charles等专业抓包工具的...全文涵盖了从基础到进阶的多种技术手段,为开发者解决接口定位难题提供了全面指导。(150字)
- 2023-06-08 21:44坚持不懈的大白的博客 仅仅是小编总结的三点而已,可能不是很全面,如果之后小编了解到新的知识点,可能还会增加的哈!
- 2022-06-28 09:55隔壁李学长的博客 最近放暑假,闲来无事,爬点东西来...BiliBili的视频爬取教程参考自BiliBili视频(自己爬自己,哈哈哈),城市影院的视频爬取以BiliBili为启发,自己编写。代码仅供参考,不用做其他用途。..............................
- 2020-02-29 11:11林小卫很行的博客 在爬虫实践当中,如果我们爬取的页面的编写没有做好板块的区分,或者我们选取的标签不合适,最终我们获得的结果会多提取到出一些奇怪的东西。 当使用用request获取的网页源代码里没有我们想要的数据时,需要重新...
- 2024-11-22 16:59Python_trys的博客 此时就可以观看该电影,嗯,用过的应该知道,m3u8格式的视频不在大网站上的话,非常容易卡,十分影响观影体验,于是我们选择下载电影。,然后解析播放(切记顺序不要乱),就会刷新出文件,双击点开文件,进入视频...
- 2017-10-24 23:07一身诗意千寻瀑的博客 点开上方的Herders可以找到require url请求的地址,通过观察发现requireurl中offset每次获取到都不一样,都是增加了20。 找到规律我们就可以再代码中构造url了,其中代码中的offset={},{}由后的...
- 2021-01-14 15:58明天哇哈哈的博客 点开上方的Herders可以找到require url请求的地址,通过观察发现requireurl中offset每次获取到都不一样,都是增加了20。 找到规律我们就可以再代码中构造url了,其中代码中的offset={},{}由后的format(str(i))取代...
- 2022-04-20 17:30五包辣条!的博客 学习爬虫你完全可以理解为找辣条君借钱(借100万),首先如果想找辣条借钱那首先需要知道我的居住地址,然后想办法去到辣条的所在的(可以走路可以坐车),然后辣条身上的东西比较多,有100万,打火机,烟,手机衣服...
- 2020-09-17 11:58总结来说,了解并掌握如何使用Python爬虫实现POST request payload形式的请求是网络爬虫开发中必不可少的技能,这涉及到对HTTP协议的理解、请求头的设置以及数据编码方式的选择。正确使用payload形式的POST请求,...
- 2020-12-20 08:46weixin_39699121的博客 近期,通过做了一些小的项目,觉得对于Python爬虫有了一定的了解,于是,就对于Python爬虫爬取数据做了一个小小的总结,希望大家喜欢!1.最简单的Python爬虫最简单的Python爬虫莫过于直接使用urllib.request.urlopen...
- 2021-01-21 18:19此次的目标是爬取指定城市的天气预报信息,然后再用Python发送邮件到指定的邮箱。 下面话不多说了,来一起看看详细的实现过程吧 一、爬取天气预报 1、首先是爬取天气预报的信息,用的网站是中国天气网,网址是...
- 2024-03-01 23:47齐 飞的博客 python爬虫笔记
- 2021-10-24 16:32纸照片的博客 Python爬虫批量下载百度图片
- 2025-02-13 08:54LeonDL168的博客 Python 爬虫音频数据
- 2020-11-20 18:02weixin_39789646的博客 怎么死活找不到目标数据呢?下面我带大家一起走一遍那些年我踩过的坑:异步加载XMLHttpRequest 用于在后台与服务器交换数据。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
9月19日
系统已结题
9月19日 已采纳回答
9月11日
已采纳回答
9月11日-
创建了问题
9月11日