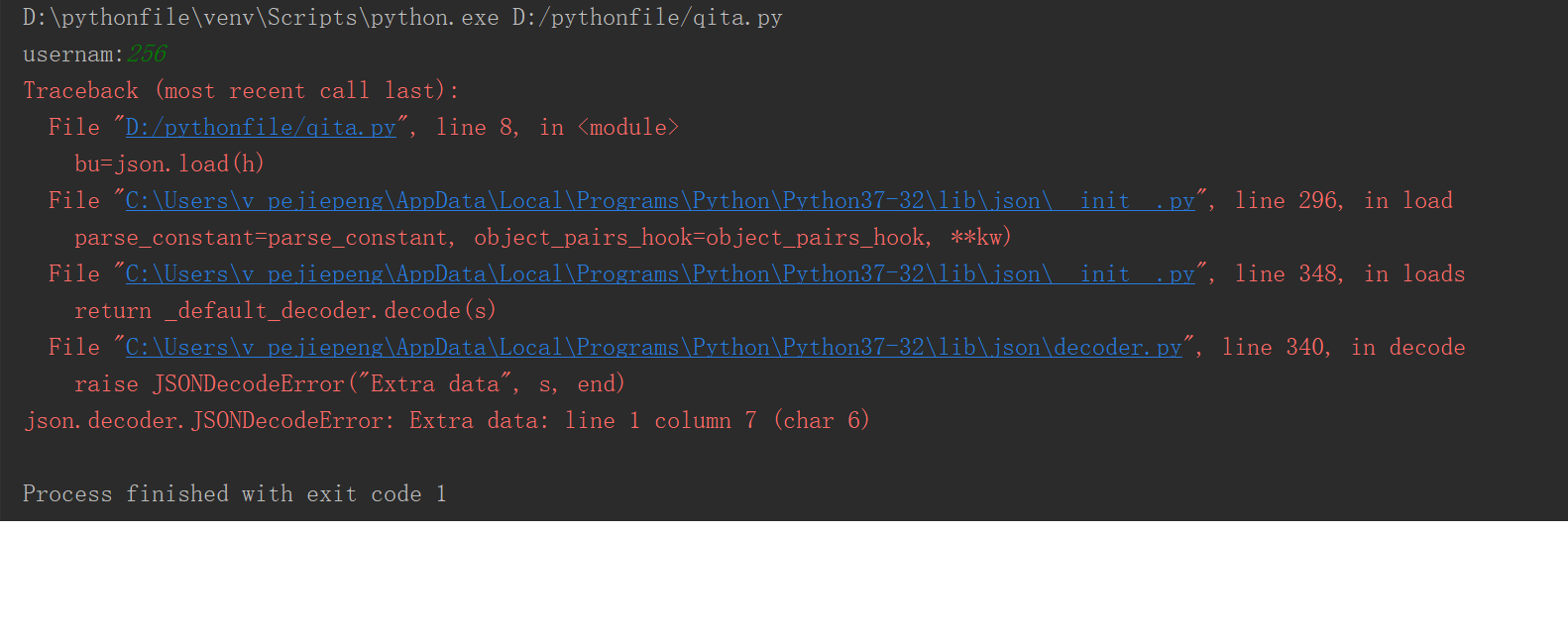
import json
while True:
username=input('usernam:')
if username!='q':
with open('username.json','a')as c:
json.dump(username,c)
with open('username.json')as h:
bu=json.load(h)
print (bu)
else:
break
代码如上,首先导入json,然后进行循环,定义一个变量为用户自定义输入的内容,判断这个变量是否等于q,不等于q,则追加自定义内容,然后并打开它,以校验用户自定义输入内容是否加入。否则则跳过此次循环。在本人用其他工具打开json文件发现数据已经写进去了。但在执行bu=json.load(h)这步时报错,请高人指点谢谢!