
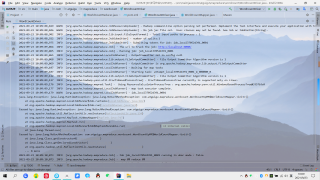
output里面没有数据,jar包好像都导上了,就是不行,
Mapper代码如下
package com.atguigu.mapreduce.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.Tool;
import java.io.IOException;
//KEYIN map阶段输入的key类型:LongWritable
//VALUEIN map阶段输入value类型:Text
//KEYOUT map阶段输出的key类型:Text
//VALUEOUT map阶段输出的value类型:IntWritable
class WordCountUpMR extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
return 0;
}
public class WorldCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
super.map(key, value, context);
//1 获取一行,数据如下
//atguigu atguigu
String line = value.toString();
//2 切割操作,成为
//atguigu
//atguigu
String[] words = line.split(" ");
//3 循环写出
for (String word : words) {
//封装outK
outK.set(word);
//写出
context.write(outK, outV);
}
}
}
}
Driver代码如下
package com.atguigu.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.获取jar包路径
job.setJarByClass(WordCountDriver.class);
//3.关联mapper和reducer
job.setMapperClass(WordCountUpMR.WorldCountMapper.class);
job.setReducerClass(WorldCountReducer.class);
//4.设置map输出的k-v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终输出的k-v类型
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("E:\\hadoop\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\hadoop\\output"));
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
Reducer代码如下
package com.atguigu.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//KEYIN reduce阶段输入的key类型:LongWritable
//VALUEIN reduce阶段输入value类型:Text
//KEYOUT reduce阶段输出的Key类型:Text
//VALUEOUT reduce阶段输出的value类型:IntWritable
public class WorldCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//atguigu,(1,1)
//ss,(1,1)
//进行累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
//写出
context.write(key,outV);
}
}







