一个关于医疗知识图谱的问答系统程序包,我用爬虫爬取网站信息后将数据整理,结果总是出现这种解码错误。网上看了好多都是说加个‘r’,'utf-8'。但是我都加了还是不行。可能是我加的位置不对?或者有别的方法。希望有朋友指教一下。
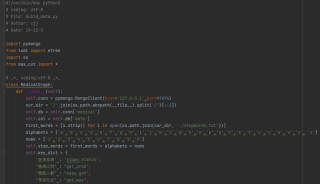
这是部分程序
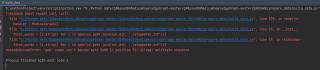
一运行就会出现这种错误

一个关于医疗知识图谱的问答系统程序包,我用爬虫爬取网站信息后将数据整理,结果总是出现这种解码错误。网上看了好多都是说加个‘r’,'utf-8'。但是我都加了还是不行。可能是我加的位置不对?或者有别的方法。希望有朋友指教一下。
 分享
分享 创建了问题
9月24日
创建了问题
9月24日


