关于开启hive的事务支持,我在网上查了很多,都说执行
INSERT INTO NEXT_LOCK_ID VALUES(1);
INSERT INTO NEXT_COMPACTION_QUEUE_ID VALUES(1);
INSERT INTO NEXT_TXN_ID VALUES(1);
COMMIT;
这四句sql,但问题是mysql的hive库没有这仨表,也没有一个说NEXT_LOCK_ID、NEXT_COMPACTION_QUEUE_ID、NEXT_TXN_ID这三个表怎么建的?哪位大神解答下,非常感谢!!!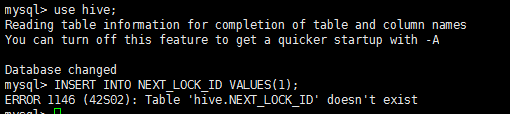

hive版本:apache版1.1.0

hive怎么开启支持单条数据的insert支持?是开启事务吗?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 l584814283 2019-06-20 09:25关注
l584814283 2019-06-20 09:25关注我的是生产环境5张表没有,但是测试环境5张表都是全的,以下是五张表的建表语句
CREATE TABLEhive.COMPACTION_QUEUE(CQ_IDbigint(20) NOT NULL,CQ_DATABASEvarchar(128) NOT NULL,CQ_TABLEvarchar(128) NOT NULL,CQ_PARTITIONvarchar(767) DEFAULT NULL,CQ_STATEchar(1) NOT NULL,CQ_TYPEchar(1) NOT NULL,CQ_WORKER_IDvarchar(128) DEFAULT NULL,CQ_STARTbigint(20) DEFAULT NULL,CQ_RUN_ASvarchar(128) DEFAULT NULL,
PRIMARY KEY (CQ_ID)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE
hive.HIVE_LOCKS(HL_LOCK_EXT_IDbigint(20) NOT NULL,HL_LOCK_INT_IDbigint(20) NOT NULL,HL_TXNIDbigint(20) DEFAULT NULL,HL_DBvarchar(128) NOT NULL,HL_TABLEvarchar(128) DEFAULT NULL,HL_PARTITIONvarchar(767) DEFAULT NULL,HL_LOCK_STATEchar(1) NOT NULL,HL_LOCK_TYPEchar(1) NOT NULL,HL_LAST_HEARTBEATbigint(20) NOT NULL,HL_ACQUIRED_ATbigint(20) DEFAULT NULL,HL_USERvarchar(128) NOT NULL,HL_HOSTvarchar(128) NOT NULL,
PRIMARY KEY (HL_LOCK_EXT_ID,HL_LOCK_INT_ID),
KEYHIVE_LOCK_TXNID_INDEX(HL_TXNID),
KEYHL_TXNID_IDX(HL_TXNID)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE
hive.NEXT_COMPACTION_QUEUE_ID(NCQ_NEXTbigint(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE
NEXT_TXN_ID(NTXN_NEXTbigint(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE
next_lock_id(NL_NEXTbigint(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2025-01-01 14:57輕栀的博客 为企业制定决策、提供数据支持的,可以帮助企业改进业务流程提高产品质量等。DW不是数据最终目的地,而是为数据最终目的地做好准备,这些准备包括对数据的备份,清洗,转义、分类、重组、合并、拆分、聚合,统计等。...
- 2024-10-09 19:24编码人生_的博客 文章目录一、数据仓库1.1、数据仓库概念1.2、数据仓库核心特征1.3、数据库和数据仓库的区别1.4、数据仓库分层架构[**重要**]1.5、ETL和ELT二、Apache Hive2.1、Hive的概念2.2、Hive的架构组件(非常重要)2.3、Hive和...
- 2024-10-28 18:45自节码的博客 Hive是一个构建在Hadoop上的数据仓库软件,它提供了类似SQL的查询语言,使得用户可以用SQL来查询存放在Hadoop上的数据。Hive是一种结构化数据的存储和查询机制,它可以将SQL语句转换为MapReduce任务在Hadoop上执行。...
- 2023-06-06 15:53一瓢一瓢的饮 alanchanchn的博客 比如,如果表具有分区,则load命令没有指定分区...详见Hive事务的支持段落。所有合并都是在后台完成的,不会阻止数据的并发读、写。对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据。
- 2021-03-27 17:05赵广陆的博客 select3 multiple inserts多重插入4 dynamic partition insert动态分区插入4.1 功能4.2 配置参数4.3 案例:动态分区插入5 insert + directory导出数据6 Hive Transaction事务6.1 Hive事务背景知识6.2 Hive事务表...
- 2024-03-09 08:50OutRoading的博客 Apache Hive是一款建立在Hadoop之上的开源系统,可以将存储在Hadoop文件中的,基于表提供了一种类似SQL的查询模式,称为,用于访问和分析存储在Hadoop文件中的大型数据集Hive核心是将 HQL转换成MapReduce程序,然后...
- 2023-08-17 21:16逆风飞翔的小叔的博客 hive事务表使用详解
- 2026-02-24 00:19AI云原生与云计算技术学院的博客 Apache Hive作为构建在Hadoop之上的数据仓库基础设施,通过类SQL语言HiveQL将复杂的MapReduce程序抽象为结构化查询,天然适合处理社交媒体场景下的大规模数据离线分析任务。本文聚焦Hive在社交媒体数据处理中的核心...
- 2023-04-27 17:27bst@微胖子的博客 Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。简单、容易上手 (提供了类似 sql...
- 2024-05-22 01:09墨尔本、晴的博客 Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据映射为一张表,并提供类SQL查询功能。 Hive的本质是一个Hadoop客户端,用于将HQL(HiveSQL)转化成MapReduce程序。 (1)Hive中每张表的...
- 没有解决我的问题, 去提问
