关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
末日流光
2021-09-26 16:06
采纳率: 100%
浏览 29
首页
有问必答
已结题
为什么爬取的网址名称后面的_2,_3,掉了
有问必答
python
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN专家-HGJ
2021-09-26 16:10
关注
你在解析时用的正则表达式吗?,试试用soup.find_all或soup_select()方法去获取看看。
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
爬取
数据保存为Json格式的代码示例
2020-09-19 11:41
在
Python
编程中,经常需要从网络上
爬取
数据,然后将其存储为便于处理和分析的格式,如JSON。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。在本篇...
python
爬取
高德poi数据_高德地图之
python
爬取
POI数据及其边界经纬度
2021-02-10 18:28
wesinnn的博客
目前高德的边界没法批量
爬取
,不过可以采用百度地图的接口来替代,目前用着还可以,参见这里:为了方便大家,不用再为安装环境,以及运行报错等问题困扰,目前已经将POI数据
爬取
做成一个在线公开的数工具,地址奉上...
python
爬取
付费电影思路_
python
3爬虫
爬取
猫眼电影TOP100(含详细
爬取
思路)
2020-12-08 08:24
weixin_39935319的博客
待
爬取
的网页地址为https://maoyan.com/board/4,本次以requests、BeautifulSoup css selector为路线进行
爬取
,最终目的是把影片排名、图片、
名称
、演员、上映时间与评分提取出来并保存到文件。初步分析:所有网页上...
python
爬虫
爬取
京东商品评价_
python
爬取
京东商品信息及评论
2021-02-10 18:54
周含露的博客
'''
爬取
京东商品信息:功能: 通过chromeDrive进行模拟访问需要
爬取
的京东商品详情页(https://item.jd.com/100003196609.html)并且程序支持多个页面
爬取
,输入时以逗号分隔,思路: 创建webdriver对象并且调用get方法...
python
爬取
网易云评论_
Python
- 网易云热门评论
爬取
2021-03-06 16:18
满船清梦压土豆儿的博客
导语今天需要跟大家分享关于如何
爬取
网易云热门评论的。对于网易云,相信大家都不陌生。博主便常常使用网易云音乐,一方面是为了听歌,愉悦身心,另一位方面是冲着网易云评论来的。在网易云音乐,相信你总能阅读到...
python
爬取
京东手机数据_用scrapy
爬取
京东的数据
2020-11-21 01:04
weixin_39526185的博客
一、项目介绍主要目标1、使用scrapy
爬取
京东上所有的手机数据2、将
爬取
的数据存储到MongoDB环境win7、
python
2、pycharm技术1、数据采集:scrapy2、数据存储:MongoDB难点分析和其他的电商网站相比,京东的搜索类
爬取
...
python
爬取
qq音乐标签_
Python
爬取
qq音乐的过程实例
2020-12-05 05:17
weixin_39564605的博客
一、前言qq music上的音乐...下面开始找吧(讲的不对不要笑我)二、
Python
爬取
QQ音乐单曲之前看的慕课网的一个视频, 很好地讲解了一般编写爬虫的步骤,我们也按这个来。爬虫步骤1.确定目标首先我们要明确目标,本次爬...
Python
爬虫入门教程!手把手教会你
爬取
网页数据_
python
爬取
网页数据
2024-05-06 12:42
rr8f2haQf的博客
在学习
python
中有任何困难不懂的可以微信扫描下方CSDN官方认证二维码加入
python
交流学习多多交流问题,互帮互助,这里有不错的学习教程和开发工具。[[CSDN大礼包:《
python
安装包&全套学习资料》免费分享]]安全链接...
python
爬取
公众号阅读量_
Python
爬取
微信公众号文章以及在看阅读数
2020-12-20 16:05
weixin_39688870的博客
这几天获取微信文章的在看阅读评论数十分麻烦,发现网上的教程都是17年以前的...一、获取公众号文章1、利用爬虫
爬取
数据最基本的也是最重要的就是找到目标网站的url地址,然后遍历地址逐个或多线程
爬取
,一般后续的...
python
爬取
微信公众号_
python
爬取
微信公众号
2020-12-03 11:16
weixin_39669204的博客
需要安装
python
selenium模块包,通过selenium中的webdriver驱动浏览器获取Cookie的方法、来达到登录的效果pip3 install seleniumchromedriver:chromedriver与chrome的对应关系表2.微信公众号登陆地址:...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
10月4日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
9月26日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
9月26日

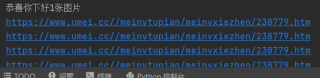
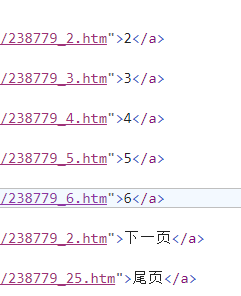

 分享
分享 系统已结题
10月4日
系统已结题
10月4日 已采纳回答
9月26日
创建了问题
9月26日
已采纳回答
9月26日
创建了问题
9月26日


